Hello everyone,
I see FreeBSD as a very powerful option for designing a formidable high availability SAN. The storage options in FreeBSD are amazing, yet there are so many ways of doing this that my head is spinning, and I am trying to find what could be considered good practices. Here is the scenario I have in mind
I know that FreeBSD also comes with the daemon
Using iSCSI and mirroring the secondary servers can provide extra read operations, storage servers can be added for a horizontal scalability, and jails can have another virtual ZVOL added and have the mirror be expanded into RAID10 (maybe, just thinking out loud).
Does anybody see any problems with this design, or things to keep in mind? I still have no clue how to make the jails be redundant as well, maybe HAST can be useful there and have the jails userland be redundant.
I would love to hear your experiences with designing a HA-SAN")
I see FreeBSD as a very powerful option for designing a formidable high availability SAN. The storage options in FreeBSD are amazing, yet there are so many ways of doing this that my head is spinning, and I am trying to find what could be considered good practices. Here is the scenario I have in mind
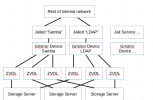
- As an example, the data to be stored in the SAN is general storage, think of a company's messy fileserver. Random files of random sizes being accessed at random times.
- At least 2 servers are dedicated purely to host large zpools. RAID10 for the best performance, or RAID-Z2 for a balance of redundancy and storage space. Eventually another server can be added for scaling horizontally.
- Another server will be dedicated to host jails containing a basic userland and have the jails be a client of the storage servers. Assume that the network conditions are perfect and it's not a bottleneck.
- For simplicity, lets consider a "Samba fileserver" jail on the dedicated jail server.
- Storage servers share via iSCSI a ZVOL each of the same size to the Samba Jail. We assume the jail is properly configured to have it's own
devddevices. - The Samba Jail uses
gmirrorto create a mirror device out of the two ZVOLS. The jail has a mirrored block disk device available. Should encryption be needed, using a layer of GEOMGELIcan be added. (Decryption key on the jailed userland?) - Samba Jail partitions the networked mirrored disk and uses UFS as it's filesystem. (I don't think that the jail should use ZFS, considering the storage servers are using ZFS already on the ZVOLs)
- The samba jail has all the Samba configuration on its jailed userland and uses as its data share the iSCSI mirrored disk.
- Storage servers share via iSCSI a ZVOL each of the same size to the Samba Jail. We assume the jail is properly configured to have it's own
- Writes are a bit slower since the data must reach both storage servers, but reads should be faster.
- If one storage server goes down, the Samba Jail has it's data available albeit at a degraded state since one block device is missing. Once the storage server comes back up, the jailed
gmirrorshould copy the missing data on the late ZVOL.
I know that FreeBSD also comes with the daemon
hastd which literally means "Highly Available storage", but I think it works more as a failover structure and having the secondary servers be "useless" waiting for a fail to happen is a bit of a waste. Using iSCSI and mirroring the secondary servers can provide extra read operations, storage servers can be added for a horizontal scalability, and jails can have another virtual ZVOL added and have the mirror be expanded into RAID10 (maybe, just thinking out loud).
Does anybody see any problems with this design, or things to keep in mind? I still have no clue how to make the jails be redundant as well, maybe HAST can be useful there and have the jails userland be redundant.
I would love to hear your experiences with designing a HA-SAN