My server became unavailable and became stuck in a boot loop when I rebooted. Looks like a kernel panic related to zfs. I'm thinking it may be due to a full disk. Not sure how to resolve. The only error that jumps out is...
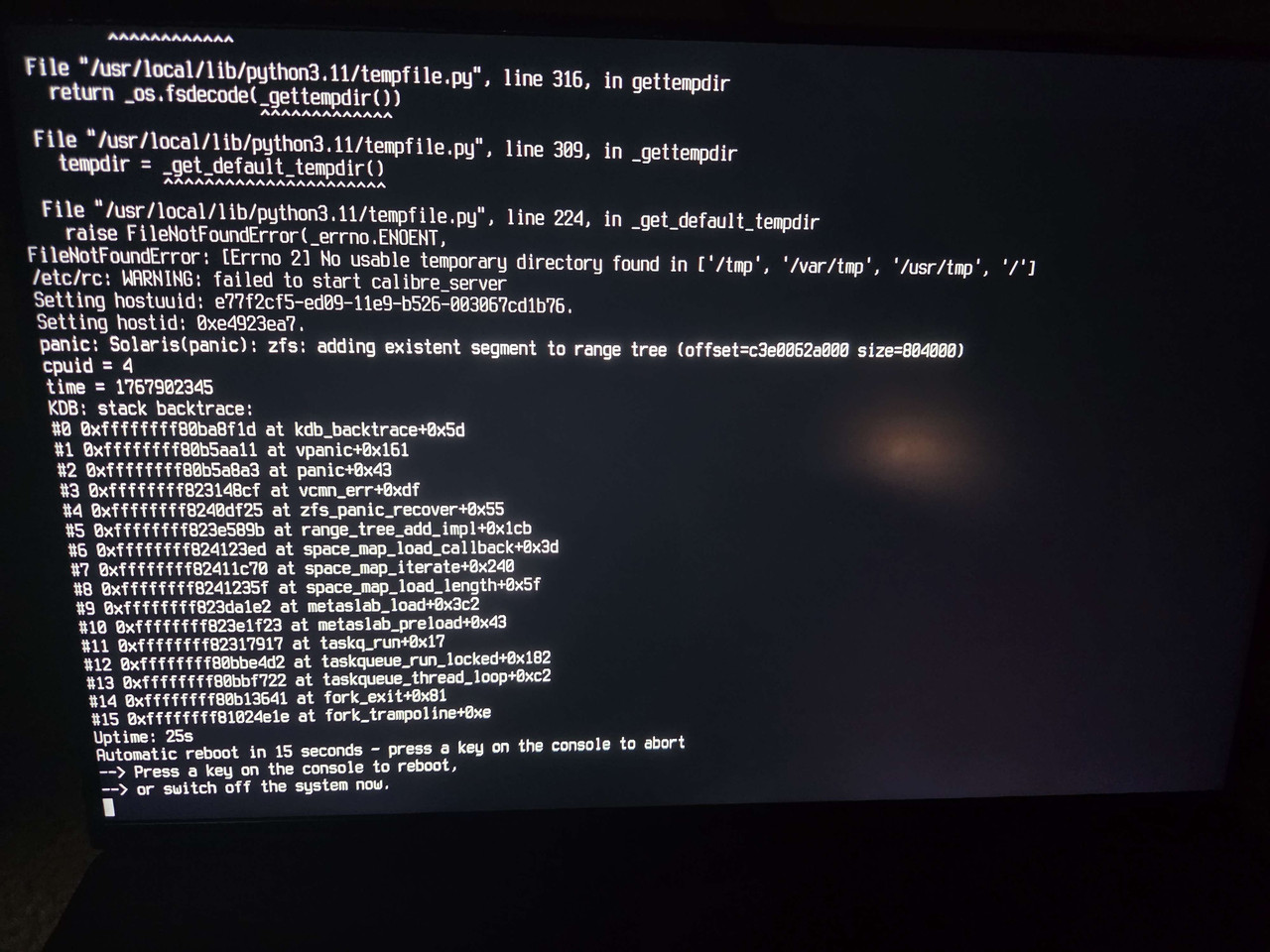
Code:
panic: Solaris(panic): zfs: adding existent segment to range tree

")