I have a system with 8 GB of RAM on an AWS instance.
running MariaDB. Over time, a growing portion of the total memory seems to disappear from FreeBSD's line of sight.
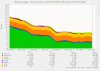
Starting here,
to this, after a few hours.
Where could tbe missing 6GB be?
Code:
root@backslave-main-pr:/usr/home/m2msadmin # uname -a && dmesg | grep memory
FreeBSD backslave-main-pr 12.1-RELEASE-p2 FreeBSD 12.1-RELEASE-p2 GENERIC amd64
real memory = 9556721664 (9114 MB)
avail memory = 8170881024 (7792 MB)running MariaDB. Over time, a growing portion of the total memory seems to disappear from FreeBSD's line of sight.
Starting here,
top reports 8591 MB total
Code:
root@backslave-main-pr:/usr/home/m2msadmin # top | grep Mem
Mem: 642M Active, 379M Inact, 1230M Wired, 784M Buf, 5556M Freeto this, after a few hours.
top reports 2284 MB total
Code:
root@backslave-main-pr:/usr/home/m2msadmin # top | grep Mem
Mem: 110M Active, 148K Inact, 388K Laundry, 1268M Wired, 783M Buf, 123M FreeWhere could tbe missing 6GB be?