Ok , so I set readonly=off and ran savecore.Perfect, almost there. Assuming you have enough free space in /var run this from single mode:/etc/rc.d/savecore startand check the /var/crash afterwards.
edit: actually in single mode your fileset(s) may be in readonly mode. Do you know how to remount it read-write?
/a and run the savecore command manually: savecore /a /dev/ada0p2 - it will save it to that directory directly and hence will be on USB key right away.When I tried less on one of the files it said there was no debugger or something like that. Now trying to copy the files, one of them is 450+ mb as well. Will post files sooner.What does it mean it doesn't work ? That's the text summary of the crash, it should be readable. Copy the whole contents of the /var/crash to that usb stick and share it from there.
Oops logged out now - really need to focus on recoering data and getting my system back now.Ok, you don't have gdb installed. Not a problem. Along with that please can you docksum /boot/kernel/kerneland post what version of FreeBSD you're running exactly?
core.txt.0 contains only
info.0 contains onlyUnable to find a kernel debugger.
Please install the devel/gdb port or gdb package.
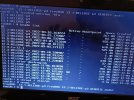
info.last contains onlyDump header from device: /dev/ada0p2
Architecture: amd64
Architecture Version: 2
Dump Length: 477515776
Blocksize: 512
Compression: none
Dumptime: 2022-12-12 12:21:49 +0400
Hostname: toaster
Magic: FreeBSD Kernel Dump
Version String: FreeBSD 13.1-RELEASE-p3 GENERIC
Panic String: VERIFY3(0 == zap_add_int(zfsvfs->z_os, zfsvfs->z_unlinkedobj, zp->z_id, tx)) failed (0 == 97)
Dump Parity: 3470720052
Bounds: 0
Dump Status: good
and then there's vmcore binary files I think which are 450+ mbDump header from device: /dev/ada0p2
Architecture: amd64
Architecture Version: 2
Dump Length: 477515776
Blocksize: 512
Compression: none
Dumptime: 2022-12-12 12:21:49 +0400
Hostname: toaster
Magic: FreeBSD Kernel Dump
Version String: FreeBSD 13.1-RELEASE-p3 GENERIC
Panic String: VERIFY3(0 == zap_add_int(zfsvfs->z_os, zfsvfs->z_unlinkedobj, zp->z_id, tx)) failed (0 == 97)
Dump Parity: 3470720052
Bounds: 0
Dump Status: good
Panic String: VERIFY3(0 == zap_add_int(zfsvfs->z_os, zfsvfs->z_unlinkedobj, zp->z_id, tx)) failed (0 == 97)freebsd-version -kruPlease check imagefreebsd-version -kru
HW details - at least some description.
+stack backtrace and we have all info needed
So p3 is a month old, I'd like to backup from p4/p5 .... How can I make that happen?p4 didn't involve the kernel, it only had some userland updates. P5 is also just a couple of userland updates. So a p3 kernel is perfectly normal.
Thank you! Please let me know if there's anything else you need from me or if there's a solution to my issue!I opened PR 268333.
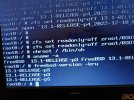
I see system is panicing during /tmp cleanup. Idea is to either disable this fileset or create a new one. The thing is I don't want to touch ZFS too much as we don't know what state is it in. Disabling it, however, should be ok.
In single mode do zfs set mountpoint=none zroot/tmp and reboot. This dataset would not be mounted but rather /tmp in / would be used. This could be the convenience you need to get to the full system and do backup from there.
zfs rename zroot/tmp zroot/tmp.broken If that works I would create a new tmp; zfs create -o mountpoint=/tmp zroot/tmp chmod 1777 /tmp as it needs the sticky(7) bit there.Yup. I've gleaned from reading too many of the OP's posts that it's an older system prone to overheating. My stab in the dark is that some aging component has started to fail, but only shows symptoms when the system overheats. Not too many paths forward besides new hardware.The thing is - we are all guessing. We don't know what's happening.
geli attach /dev/da0p3
Enter passphrase:
sudo mount /dev/da0p3.eli /mnt
mount: /dev/da0p3.eli: No such file or directory
 , Firefox won't start without asking me to create a new profile when I had multiple windows running. And Chrome won't even start. That's where I had some of my important stuff.
, Firefox won't start without asking me to create a new profile when I had multiple windows running. And Chrome won't even start. That's where I had some of my important stuff.What specifically gives it away that it has overheating issues?OP's posts that it's an older system prone to overheating.
Definitely. All of them are rockstars for having gone out of their way to help me ?I admire the time and effort you and others have spent trying to save the OP's data, though.
What specifically gives it away that it has overheating issues?
Also the reboots during compilations are pretty typical effects of overheating....this machine is pretty old so I guess that should be reasonable? Was already having temp issues when overloaded...
cp -rp /usr/home/c1utt4r/.config/chromium /var/crash
rm -rf /usr/home/c1utt4r/.config/chromiumThis is the link that the result which shows error points to https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A/ .... seems like a metadata level corruption .... not sure how to get rid of it .... but first I guess I need to salvage whatever data remainslooks a lot like https://support.oracle.com/knowledge/Sun Microsystems/2421977_1.html
just i can't remember my larry support account
Passphrase is correct - it attaches itself but it doesn't mount. Here is the output to showIf da0p3.eli doesn't exist after you entered passphrase you didn't enter a proper one then. Syslog (/var/log/messages) might give you more information about that.
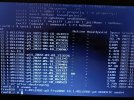
sudo zdb -l /dev/da0p3.eli
------------------------------------
LABEL 0
------------------------------------
version: 5000
name: 'zroot'
state: 0
txg: 3557598
pool_guid: 10535025700179738651
hostid: 2647270205
hostname: ''
top_guid: 1525963299974165836
guid: 1525963299974165836
vdev_children: 1
vdev_tree:
type: 'disk'
id: 0
guid: 1525963299974165836
path: '/dev/ada0p3.eli'
phys_path: 'id1,enc@n3061686369656d30/type@0/slot@3/elmdesc@Slot_02/p3/eli'
whole_disk: 1
metaslab_array: 67
metaslab_shift: 31
ashift: 12
asize: 311476617216
is_log: 0
DTL: 284
create_txg: 4
features_for_read:
com.delphix:hole_birth
com.delphix:embedded_data
labels = 0 1 2 3
I was hoping to use zfs for file permissions, etc being the same, and possibly easier. If data is corrupted (as it seems) maybe zfs is a better option than rsync ?It's up to you how you decide to do a backup, there are more ways to skin a cat. I would opt for filesystem backup using rsync and would not do zfs send. I mean as you do have corrupted pool issue is there one way or the other. It would be my personal preference though.
zpool import you should see the pool.zdb -l /dev/da0p3.eli
path: '/dev/ada0p3.eli'