It's entirely possible that you are conflating a collection of maladies.
The problem is that the possibilities being canvassed are growing at a pace.
So you need to narrow down the search be eliminating variates, and move forward one step at a time.
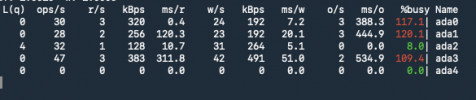
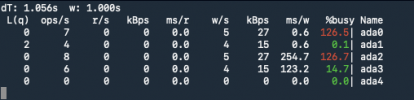
Yes, SMR disks are crap for ZFS. Their achilles heel is mostly with deletions and re-writing. They will never work well with a database that needs to be constantly updated. Deleting database rows is going to be slow. Resilvering a replacement disk will be a nightmare -- it will take an eternity (like two weeks instead of a day), and the system will run like a dog for the entire time. Your only way forward with these SMR disks is to eventually replace them.
So to trouble-shoot, quiesce your applications, your databases, and your disks. Then move forward, one step at a time. You need to eliminate mis-configuration before considering hardware problems.
Several people have mentioned different ways in which delays in every DNS lookup can multiply to kill application performance. This is experience speaking. It needs to be near top of the list for your investigations.
Time DNS lookups (forward and reverse) on your server and your client. Repeat the tests several times. Not all DNS queries are resolved in the same way. This is why I suggested you test ssh connections above.
Run the iocage list. Is it still slow?
 They go to quite a length to fill their spec sheets with useless statements, while not telling the relevant facts. And then they resort on the position that a consumer desktop drive (like the "DM") is not suited for databases.
They go to quite a length to fill their spec sheets with useless statements, while not telling the relevant facts. And then they resort on the position that a consumer desktop drive (like the "DM") is not suited for databases.