
iTWire - Uni group slammed over submitting known buggy patches to Linux kernel
A group from the University of Minnesota has come in for a tongue-lashing from the normally mild-mannered Linux developer Greg Kroah-Hartman, the maintainer of the stable kernel. Kroah-Hartman blew up after the group submitted patches to the kernel which were known to be buggy. He said in a post...
Intentionally buggy commits for fame—and papers
A buggy patch posted to the linux-kernel mailing list in early April was apparently the last s [...]
 lwn.net
lwn.net

I am not interested in Linux, it starts already that I dislike the name, and my dislike by far does not end at this point. I like FreeBSD, and once I read the story, the first question which came to my mind was, whether Mr. Wu tried to interfere into FreeBSD development as well. So, I searxed for the keywords FreeBSD "Quishi Wu".
According to what I found so far, he did not, at least not by using his real name. However, what I found is, that Quishi Wu seems to be a bare bone scientist, who wrote very well elaborated papers on security issue, which probably most of those who are referring to the issue as "Intentionally buggy commits for fame—and papers" didn't read, and even I they had, won't understand much beyond the abstract of it:
- Detecting Missing-Check Bugs via Semantic- and Context-Aware Criticalness and Constraints Inferences [PDF]
- Automatically Identifying Security Checks for Detecting Kernel Semantic Bugs [PDF]
- Precisely Characterizing Security Impact in a Flood of Patches via Symbolic Rule Comparison [PDF]
- Detecting Kernel Memory Leaks in Specialized Modules with Ownership Reasoning [PDF]
- Understanding and Detecting Disordered Error Handling with Precise Function Pairing [PDF]
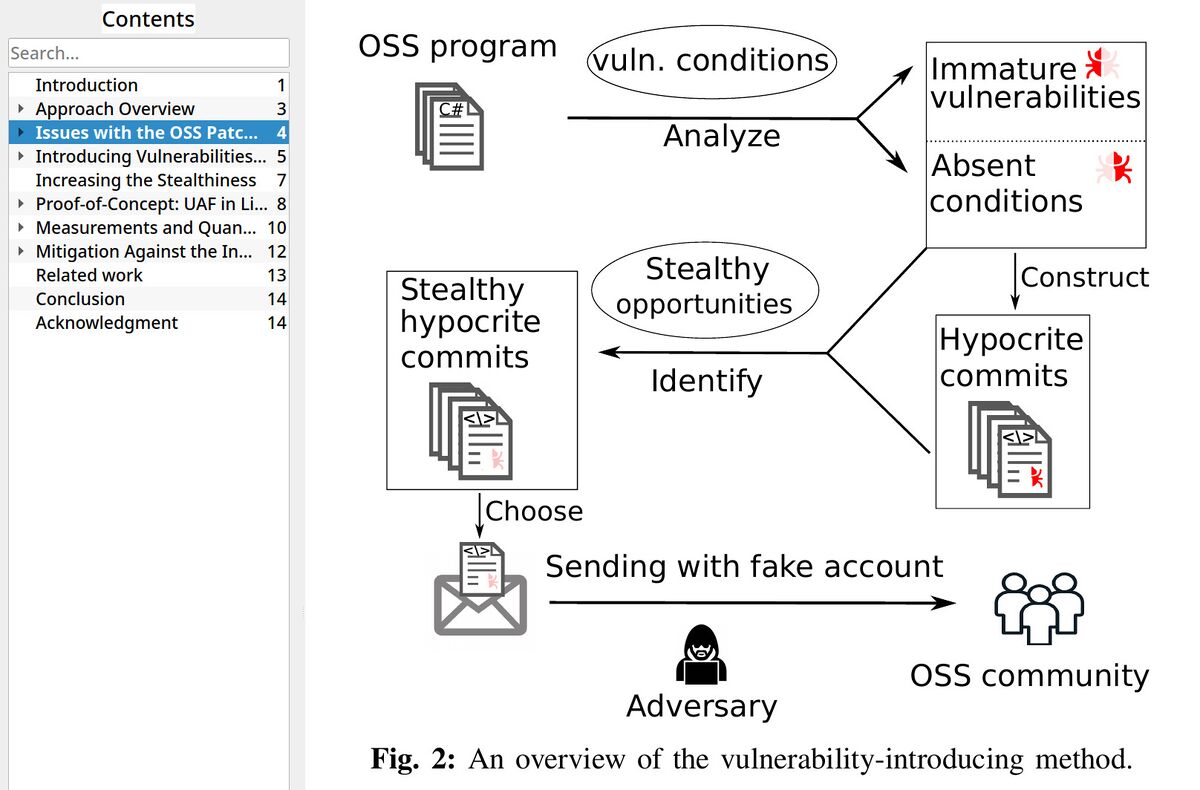
- On the Feasibility of Stealthily Introducing Vulnerabilities in Open-Source Software via Hypocrite Commits [PDF]
My conclusion, there are scientists and there are the folks, the first ones know what they are doing, while the others believe that they know something.