cracauer@
Developer
This is interesting. Will try to keep in mind. Hopefully I solve this issue for now by scrubbing but yes crashing upon compiling earlier does make me still wonder if it could be a RAM issue.
Could also be the CPU mixing up a bit here and there. That's what mprime/prime95 tests.
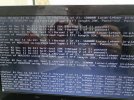
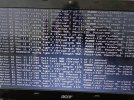
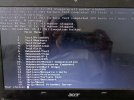
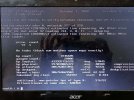
Even if you clear the ZFS errors the question remains how it got corrupted in the first place.
")