I recently created a new port for
iocaine:
PR 287944
Iocaine is one of several nepenthes-inspired tarpits and also aims to lure in AI crawlers and endlessly feeds them random garbage.
I simply divert requests from all known crawler user agents [1] to it (they can still acces the robots.txt, but anything else goes to iocaine), as well as everything that tries to connect to an invalid server_name, as it seems connecting to server_name 'localhost' is very popular amongst bots that randomly try out wordpress vulnerabilities/misconfigurations and I don't mind feeding those script kiddies garbage as well...
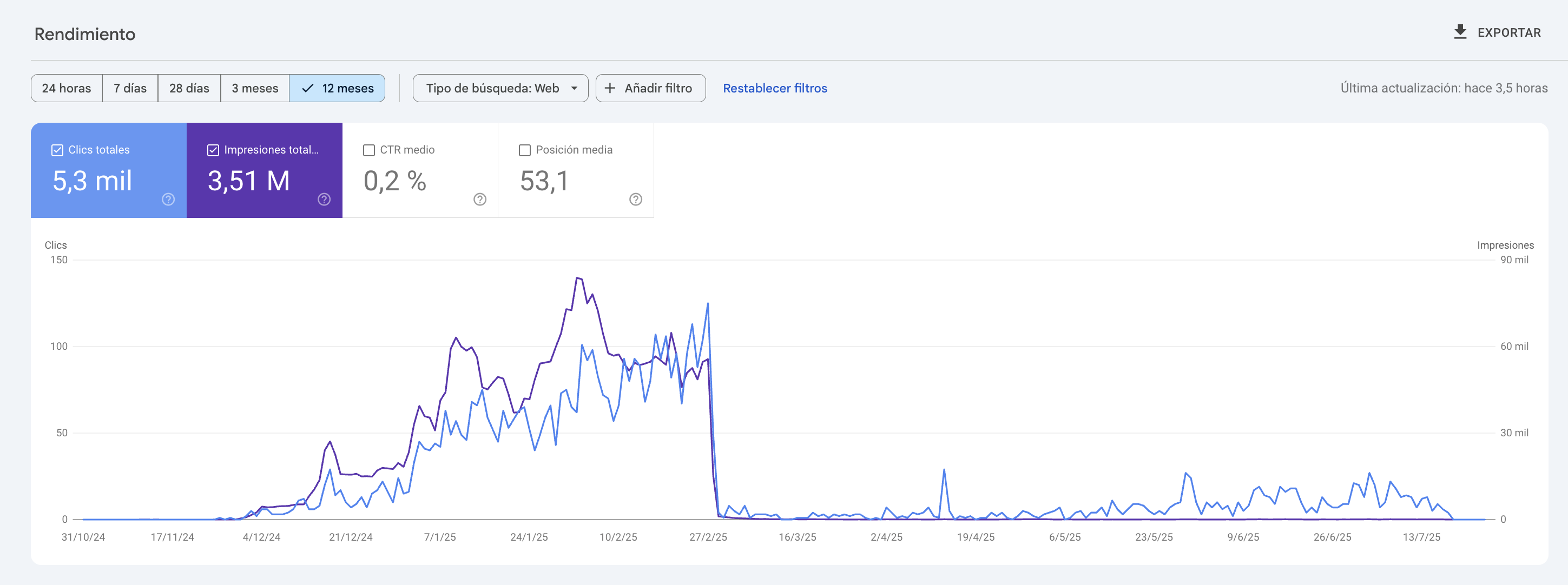
True, this won't catch crawlers that spoof their user agent - but it seems even if they blatantly ignore any robots.txt directives, the cretins that program such crap still take some pride in showing off by presenting their correct user agent. At least I haven't had any spikes in crawler-induced traffic since installing iocaine. Before that, those garbage-collectors inflated my monthly bunnynet-bill more than once by scanning frenzily through thousands of logfiles on my pkg/poudriere frontend (I only had some geofencing at bunnynet in place, which obviously doesn't help against that globally hosted pest)
Within a few weeks I've already fed several hundreds (!!) of GB of garbage to mainly the openai GPT crawler, which seems to be the most persistent and robots.txt-ignorant of them all.
[1] a curated and frequently updated list can be found at
https://github.com/ai-robots-txt/ai.robots.txt





")

