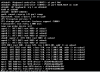
I agree. When it prints "da0 at mps1 bus 0 scbus1 target 0 lun 0", it is done with disk da0. What is it working on right now? We don't know (since it doesn't finish), but most likely the next disk on the same controller. You say the power consumption goes sky high; that probably means that the CPU is working like mad. So here's my educated guess: Something is wrong with disk da1 (the second SSD); or to be more exact: something is wrong with the interaction of da1, the LSI card and its firmware, and the FreeBSD driver that's eating all the CPU. Just pull that disk out, reboot, and see what it happens. If that fixed the problem, switch the physical connection of the two disks; that will probably cause them to be initialized in the opposite order. This experiment will tell us whether the problem is always this particular SSD, or whether the problem is whatever disk happens to be second. You could even move the problem disk to the other server, and see what happens.
Did you check that the two SSDs (and all disks in general) have up-to-date firmware versions?
My next proposal is unrealistic: Once you have narrowed down the problem to a particular disk, attach a SAS analyzer to the connection. My educated guess is that the hang with high power consumption happens because something in the device driver (FreeBSD) or Firmware (LSI) goes into a tight loop, caused by some unusual condition; attaching the SAS analyzer will help us find out whether we're communicating with the disk in that loop, and if yes, it will probably tell us what conditions causes the upset. Alas, you probably don't own a SAS analyzer, and even if you could borrow/rent/buy one (they are tens of thousands), learning how to use it takes a week or two.
In general, I agree with LSI controllers being the best quality that's out there. But they are not perfect. Sometimes their drivers or firmware have bugs. Some firmware versions have such nasty bugs that in my previous jobs we had a list of firmware versions that are prohibited from being used at customer sites (from vague memory it was something about FW 19.x versus 20.x, but don't rely on that). The good news is that LSI/Broadcom (the disk controller division was merged/sold, first to Avago, then to Broadcom) is very good about fixing problems once they hear about them. Again, it's unrealistic for you as an individual user to reach into their engineering department, but a phone call to their support line might be useful (both to hear whether they have advice, and to let them know that a problem has been seen).
Thanks for this really useful reply, ralphbsz. In line with your recommendations, I have performed the following tests.
First I should say that while the problem does occur during a reboot (I'd say on average one in four reboots), it seems to happen on every boot-up just after powering-on.
The disks have the same firmware version, there is a newer version available. Intel doesn't say much about it, but thomas-krenn.com says it fixes:
Code:
These firmware versions contain the following enhancements:
• Optimized drive shutdown sequence for better handling during poor system shutdown
• Improved power on behavior when resuming from an unsafe shutdown.
• Improvements to PS3 resume behavior
• Improvements to PHY initialization process
• Improvements to PERST# and CLKREQ# detection for corner case issues
• Improved end of life management of bad blocks for better reliability
These firmware versions contain fixes for the following issues:
• Fixed potential issue of incorrect data may be read during resume from low power state
Several of these fixes sound like something that could be related to the issue I am facing.
I have also observed that once the system is hung it stays hung, and even if I yank the disk that it seemed to be complaining about it is stuck in that hung state.
I just tried powering-on the system with only da0/SSD0 in, and it still hangs with the same error message.
I then shut the power, plugged in da1/SSD1 and disconnected da0/SSD0 and booted up, and on the first boot the system came up fine. I then rebooted 9 times and and on the 10th time it hung at boot with the same error as before.
Then I proceeded to swap the physical location of the disks, first trying to move SSD0 to the location of SSD1 (With only SSD0 plugged in), and this time I managed to get through 10 reboots, and a few cold boots without the hang. Although, while I didn't get the error this time, the fact that I only got it the 9th time in the previous test makes this result somewhat tentative.
Then I shut down, plugged in SSD1, so that both SSDs were in, but in opposite locations as opposed to the original locations. First boot from cold went fine (At this point, I needed do
zpool scrub a few times to be back in business), but after one or two reboots, it hanged again, same error, however this time "da0" would be SSD1.
So from this we can conclude: Both SSDs can trigger the hang, both on their own, and when together in either location.
Another thing that just struck me is that, the other server (Where the hang does not occur) has six hard drives in addition to the two SSDs. On both servers the SSDs are connected to the onboard controller which is second on the PCI-E bus (The first discrete card comes first on the PCI-E bus) as can be seen on the listing that I posted earlier. I have two hard drives on each controller card, so that makes the first two hard drives be da0 and da1, and the two SSDs are da2 and da3. This means that on the server where I don't get this problem the SSDs do not come in as da0 and da1. I should mention though, that I installed and configured FreeBSD on both of them "simultaniously", which is why I noticed that only one of them hangs. During the installation, I had the hard drives unplugged, but relatively soon after finishing the installation, I installed the hard drives on the first server.
Because of this, I took two old 500 GB SATA hard drives, and put onto the first discrete controller, and put the SSDs back in their original locations. With the first discrete controller card being first on the PCI-E bus and the onboard controller coming in second, this makes the two SSDs be da2 (SSD0) and da3 (SSD1). First boot from power-on went smoothly, and afterwards I maanged about 15 reboots until I had to get some sleep. I just did two power-ups and it seems to boot-up reliably now.
So it would appear that the combination of LSI firmware, the SSDs and the FreeBSD mps driver somehow does not like these SSDs being first in the line of being probed. So until I install drives in this second server, these old 500 GB drives seem to fix the issue. I might well update the firmware, just to get the fixes that Intel mentioned, but at least the server seems to work now.
What do you make of all of this?