Just popping in with my experience.
I'm using FreeBSD 14.2 to run a Ubuntu virtual machine and have had success with the following:
Used the patch
Code:
# cd /usr/
# rm -rf /usr/src
# git clone https://github.com/beckhoff/freebsd-src /usr/src
# cd /usr/src
# git checkout -f origin/phab/corvink/14.2/nvidia-wip
# cd /usr/src/usr.sbin/bhyve
# make && make install
I installed the following. Don't know if they're all needed, but I didn't get any conflicts
Code:
# pkg install bhyve-firmware edk2-bhyve grub2-bhyve vm-bhyve-devel
The devices I wanted to pass through were the GPU and Mellanox card with the following pciconf info:
Code:
ppt0@pci0:7:0:0: class=0x030000 rev=0xa1 hdr=0x00 vendor=0x10de device=0x1bb1 subvendor=0x10de subdevice=0x11a3
vendor = 'NVIDIA Corporation'
device = 'GP104GL [Quadro P4000]'
class = display
subclass = VGA
ppt1@pci0:7:0:1: class=0x040300 rev=0xa1 hdr=0x00 vendor=0x10de device=0x10f0 subvendor=0x10de subdevice=0x11a3
vendor = 'NVIDIA Corporation
ppt2@pci0:145:0:0: class=0x020700 rev=0x00 hdr=0x00 vendor=0x15b3 device=0x1011 subvendor=0x15b3 subdevice=0x0179
vendor = 'Mellanox Technologies'
device = 'MT27600 [Connect-IB]'
class = network
subclass = InfiniBand
I set them to pptdevs for passthru using
/boot/loader.conf :
Code:
kern.geom.label.disk_ident.enable="0"
kern.geom.label.gptid.enable="0"
cryptodev_load="YES"
zfs_load="YES"
vmm_load="YES"
hw.vmm.enable_vtd=1
pptdevs="145/0/0 7/0/0 7/0/1"
and for the VM I have the following config file:
Code:
loader="grub"
grub_run_partition="gpt2"
grub_run_dir="/grub"
cpu=8
custom_args="-p 4 -p 6 -p 8 -p 10 -p 12 -p 14 -p 16 -p 18"
memory=8192M
wired_memory=yes
network0_type="virtio-net"
network0_switch="public"
disk0_dev="custom"
disk0_type="ahci-hd"
disk0_name="/dev/zvol/zroot/ubuntu_vm_disk"
passthru0="7/0/0"
passthru1="7/0/1"
passthru2="145/0/0"
pptdevs="msi=on"
uuid="38c6aa07-12c7-11f0-8e5c-0894ef4d85e6"
network0_mac="58:9c:fc:0d:bb:8a"
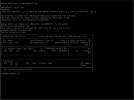
Inside of the Ubuntu virtual machine I installed nvidida-535-drivers, rebooted and got the following:
Code:
jholloway@ubuntuvm:~$ nvidia-smi
Mon Apr 7 16:16:51 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Quadro P4000 Off | 00000000:00:06.0 Off | N/A |
| 46% 35C P8 5W / 105W | 4MiB / 8192MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
So far it is working well. Plex running on the VM detects the card and is performing hardware transcoding as expected. It will even show the transcoding in nvidia-smi if I'm watching something on Plex at the time!
I have encountered one bug it seems where the VM didn't shutdown properly or something and the nvidia driver was unable to find the card. Even turning the VM off and on via the host didn't solve the problem. Fortunately when I rebooted the host and started the VM up again the problem had solved itself. I'm not sure what caused this bug as I have been unable to reproduce it, but I suspect it has something to do with either the Ubuntu VM being reset from either inside the VM, or by being shutoff from the command
vm restart ubuntu_vm.
But aside from that hiccup, both the GPU passthrough and the Mellanox passthrough are working well.
 -
-