I am having a really bizzare and apparently non-deterministic problem when trying to compile some ports on my RPI3B+ with FreeBSD 14.1. An instance of the compiler will just get "stuck" and "spin". I know those aren't very technical terms, but I dont know what else to call it. It has happened comiling both mysql80-server and mysql84-server. The RPI3B+ has four CPUs and the ports system correctly fires off up to four different processes at once, but sometimes, after crunching away for anywhere between several minutes and a few hours, one or more of the processes will just sit and use CPU time without driving ANY io or page faults but it steadly accumulates CPU time as verified with vmstat. I have been monitoring memory, swap, and other system resources, and everything seems fine. I have so far observed that from 1 to 3 processes suffer this fate during one build attempt. Smaller builds (e.g "htop") have not had the problem suggesting it may be probablistic. At first, I assumed something was catastrophically wrong, so I would do a "make clean" and start over, but recently discovered that if I killed things with INT (control c) and started them again, it would run to completion and be installable!
Anyway - this is HIGHLY annoying, and I'd really like to be able to build whatever ports I want when I need to, and so I would really welcome any suggestions you may have on how to narrow this down. Since it is so highy variant in its behavior, I'm rather at a loss on how to proceed with debugging this. This will probably end up with me submitting a bugzilla PR, but right now, I don't feel like I have enough specific information to make that possible or valuable.
I'll lay out my most recent experience, of which I also gathered the most data.
I was building mysql80-server 8.0.39 using the HEAD/latest of ports. I do have some information from earlier attempts, but I wasn't as thorough with them.
# uname -a
FreeBSD generic 14.1-RELEASE-p3 FreeBSD 14.1-RELEASE-p3 GENERIC arm64
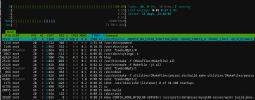
After a while, it became evident that one of the compiles was "stuck" (for lack of a better term). A compile had accumulated nearly two HOURS of CPU time. (In other build attempts, I have had one process with 11 hours and two others with over 4 hours.) At that point, I suspended the process to leave as many resources as possible to the other processes (the process status is "T"). See the "cxx_stuck" image attached. Note that it doesn't seem to matter if I've done the suspend thing or not. Eventually, "make" stopped firing off new processes. I assume it did all the work it could do without the "stuck" compile completing. I allowed the "stuck" process to continue but nothing advanced. At this point, I used "ps -p 31041 -www -o command" to capture the complete invocation of the process.
I put this in a file at ~freebsd/cmd.
Then I captured another htop screen which shows many of the processes waiting on the "stuck" one to complet - see htop_css_stuck. After that I killed the process.
Now, this might be instructive - I checked for the presense of the output (object) file for that compile and there was nothing there, though other object files were present. Maybe that gives us some insight into where the compiler is getting stuck, if it hasn't even created the output file yet. Then I ran "make build" again and it ran quickly to completion. Just for rigor, I checked for the object file, and now it was present:
After that, "make install" worked perfectly, too.
I started the database and did some checks - it appears everything is working.
So - I wanted to see just how long it actually took to compile this one file:
That's right - the compile that had accumulated over 2 hours of CPU time took 6.65 seconds to compile. I verified that I really had recompiled the file
The difference is subtle, but don't miss it - it's exactly twenty minutes later, at 13:55 instead of 13:35.
So - that's it. I'm faced with this bizzare problem. I don't know how to proceed. I know there's some wisdom to "all's well that ends well" but I really am not looking forward to not knowing every time I start major build from ports if one or more processes is going to get "stuck" for hours on end. Race condition / spin lock on creating files - file system bug? It's got to be something really strange like that, but I'm stumped.
Anyway - this is HIGHLY annoying, and I'd really like to be able to build whatever ports I want when I need to, and so I would really welcome any suggestions you may have on how to narrow this down. Since it is so highy variant in its behavior, I'm rather at a loss on how to proceed with debugging this. This will probably end up with me submitting a bugzilla PR, but right now, I don't feel like I have enough specific information to make that possible or valuable.
I'll lay out my most recent experience, of which I also gathered the most data.
I was building mysql80-server 8.0.39 using the HEAD/latest of ports. I do have some information from earlier attempts, but I wasn't as thorough with them.
# uname -a
FreeBSD generic 14.1-RELEASE-p3 FreeBSD 14.1-RELEASE-p3 GENERIC arm64
After a while, it became evident that one of the compiles was "stuck" (for lack of a better term). A compile had accumulated nearly two HOURS of CPU time. (In other build attempts, I have had one process with 11 hours and two others with over 4 hours.) At that point, I suspended the process to leave as many resources as possible to the other processes (the process status is "T"). See the "cxx_stuck" image attached. Note that it doesn't seem to matter if I've done the suspend thing or not. Eventually, "make" stopped firing off new processes. I assume it did all the work it could do without the "stuck" compile completing. I allowed the "stuck" process to continue but nothing advanced. At this point, I used "ps -p 31041 -www -o command" to capture the complete invocation of the process.
Code:
/usr/bin/c++ -DBOOST_NO_CXX98_FUNCTION_BASE -DHAVE_CONFIG_H -DHAVE_LZ4=1 -DLZ4_DISABLE_DEPRECATE_WARNINGS -DMUTEX_EVENT -D_USE_MATH_DEFINES -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS -I/usr/ports/databases/mysql80-server/work/.build -I/usr/ports/databases/mysql80-server/work/.build/include -I/usr/ports/databases/mysql80-server/work/mysql-8.0.39 -I/usr/ports/databases/mysql80-server/work/mysql-8.0.39/include -I/usr/ports/databases/mysql80-server/work/mysql-8.0.39/storage/innobase -I/usr/ports/databases/mysql80-server/work/mysql-8.0.39/storage/innobase/include -I/usr/ports/databases/mysql80-server/work/mysql-8.0.39/sql -isystem /usr/ports/databases/mysql80-server/work/mysql-8.0.39/extra/protobuf/protobuf-24.4/src -isystem /usr/local/include/editline -isystem /usr/ports/databases/mysql80-server/work/mysql-8.0.39/extra/zlib/zlib-1.2.13 -isystem /usr/ports/databases/mysql80-server/work/.build/extra/zlib/zlib-1.2.13 -isystem /usr/ports/databases/mysql80-server/work/mysql-8.0.39/extra/zstd/zstd-1.5.5/lib -std=c++17 -fno-omit-frame-pointer -ftls-model=initial-exec -O2 -pipe -fPIC -fstack-protector-strong -isystem /usr/local/include -fno-strict-aliasing -march=armv8-a+crc+crypto -isystem /usr/local/include -std=c++17 -moutline-atomics -Wall -Wextra -Wformat-security -Wvla -Wundef -Wmissing-format-attribute -Woverloaded-virtual -Wcast-qual -Wno-null-conversion -Wno-unused-private-field -Wconditional-uninitialized -Wdeprecated -Wextra-semi -Wheader-hygiene -Wnon-virtual-dtor -Wundefined-reinterpret-cast -Wrange-loop-analysis -Winconsistent-missing-destructor-override -Winconsistent-missing-override -Wshadow-field -ffunction-sections -fdata-sections -O2 -pipe -fPIC -fstack-protector-strong -isystem /usr/local/include -fno-strict-aliasing -march=armv8-a+crc+crypto -isystem /usr/local/include -std=c++17 -DNDEBUG -fPIE -Wshadow-uncaptured-local -MD -MT utilities/CMakeFiles/perror.dir/perror.cc.o -MF CMakeFiles/perror.dir/perror.cc.o.d -o CMakeFiles/perror.dir/perror.cc.o -c /usr/ports/databases/mysql80-server/work/mysql-8.0.39/utilities/perror.ccThen I captured another htop screen which shows many of the processes waiting on the "stuck" one to complet - see htop_css_stuck. After that I killed the process.
Now, this might be instructive - I checked for the presense of the output (object) file for that compile and there was nothing there, though other object files were present. Maybe that gives us some insight into where the compiler is getting stuck, if it hasn't even created the output file yet. Then I ran "make build" again and it ran quickly to completion. Just for rigor, I checked for the object file, and now it was present:
Code:
# ls -l work/.build/utilities/CMakeFiles/perror.dir/perror.cc.o
-rw-r--r-- 1 root wheel 1384384 Aug 23 13:35 work/.build/utilities/CMakeFiles/perror.dir/perror.cc.oAfter that, "make install" worked perfectly, too.
I started the database and did some checks - it appears everything is working.
So - I wanted to see just how long it actually took to compile this one file:
Code:
# time `cat ~freebsd/cmd`
8.41 real 6.30 user 0.35 sys
Code:
# ls -l work/.build/utilities/CMakeFiles/perror.dir/perror.cc.o
-rw-r--r-- 1 root wheel 1384384 Aug 23 13:55 work/.build/utilities/CMakeFiles/perror.dir/perror.cc.oSo - that's it. I'm faced with this bizzare problem. I don't know how to proceed. I know there's some wisdom to "all's well that ends well" but I really am not looking forward to not knowing every time I start major build from ports if one or more processes is going to get "stuck" for hours on end. Race condition / spin lock on creating files - file system bug? It's got to be something really strange like that, but I'm stumped.


")