I have been running combinatoric disk performance tests on the following system:
Calomel has extensive tweaks listed for both ZFS as well as configuring the LSI controllers. The only modifications I have made to my system are
However, I have also been trying to implement geli on top of ZFS. Judging from the majority of postings I have found, most users will first provision all drives in the pool with geli, then put ZFS on top of the encrypted devices. I do not want to encrypt the entire pool, however, and have instead been testing geli on top of ZFS. The benchmarks there are significantly worse; about a three fold hit for a UFS provision, and up to six fold for having an encrypted zpool in a zpool. The results below are on top of the RAID-Z3 11 drive pool:
Creating a UFS encrypted file system: Write/Rewrite/Read = 90 / 30 / 150 MB/sec
Creating an encrypted zpool (per matoatlantis): Write/Rewrite/Read = 71 / 26 / 78 MB/sec
The Xeon E5606 supports AES-NI, so I had hoped for better performance. If anyone has thoughts on improving performance of an encrypted provision on top of ZFS, I would be very interested in hearing it. Also, if this approach is flat-out a Bad Idea, I would be interested to know that, too.
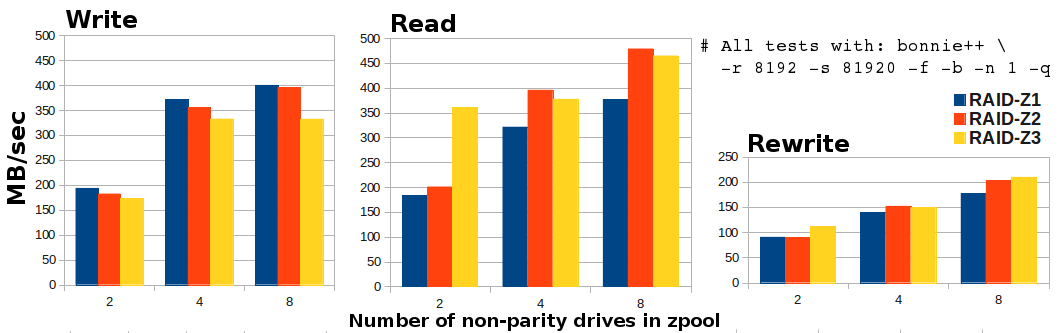
The combinatoric data were generated by a randomization script I will post below. All data points have three replicates. The standard deviation was quite tight for writes and rewrites (generally +/- 1-5 MB/sec), a little looser for reads. Raw data:
- FreeBSD 9.1
- SUPERMICRO MBD-X8DTL-iF-O Dual LGA 1366
- 2 x Intel Xeon E5606 (2.13 GHz Quad-Core)
- 6 x KVR13LR9S8/4EF (4 GB 1333 ECC; total 24 GB)
- 12 x WD30EFRX (3 TB WD Red)
- LSI00244 (9201-16i) (SAS x4 HBA)
bonnie++) are very similar to what they found:- Increasing the pool size has significant performance benefits, particularly for reads
- Increasing RAID-Z level has modest performance cost on writes
Calomel has extensive tweaks listed for both ZFS as well as configuring the LSI controllers. The only modifications I have made to my system are
zfs set atime=off. This is partly due to too many other things to do, but also a philosophy of leaving things alone that are functioning satisfactorily; For my needs the performance is more than satisfactory, so I would rather not tinker too heavily with the system. I have configured my primary pool as RAID-Z3 with 11 x 3 TB drives, which provides 20 TB of usable storage.However, I have also been trying to implement geli on top of ZFS. Judging from the majority of postings I have found, most users will first provision all drives in the pool with geli, then put ZFS on top of the encrypted devices. I do not want to encrypt the entire pool, however, and have instead been testing geli on top of ZFS. The benchmarks there are significantly worse; about a three fold hit for a UFS provision, and up to six fold for having an encrypted zpool in a zpool. The results below are on top of the RAID-Z3 11 drive pool:
Creating a UFS encrypted file system: Write/Rewrite/Read = 90 / 30 / 150 MB/sec
Code:
zfs create -V 2TB abyss/shadow
geli init -s 4096 /dev/zvol/abyss/shadow
geli attach /dev/zvol/abyss/shadow
newfs /dev/zvol/abyss/shadow.eli
mkdir /private
chmod 0777 /private/
mount /dev/zvol/abyss/shadow.eli /private
Code:
zfs create -V 2TB abyss/shadow2
geli init -s 4096 /dev/zvol/abyss/shadow2
geli attach /dev/zvol/abyss/shadow2
zpool create private2 /dev/zvol/abyss/shadow2.eliThe Xeon E5606 supports AES-NI, so I had hoped for better performance. If anyone has thoughts on improving performance of an encrypted provision on top of ZFS, I would be very interested in hearing it. Also, if this approach is flat-out a Bad Idea, I would be interested to know that, too.
The combinatoric data were generated by a randomization script I will post below. All data points have three replicates. The standard deviation was quite tight for writes and rewrites (generally +/- 1-5 MB/sec), a little looser for reads. Raw data:
Code:
Pool Write Rewrite Read WriteSD RewriteSD ReadSD
Z1+2 194 91 183 8 3 10
Z1+4 372 139 322 1 1 9
Z1+8 400 177 377 5 2 5
Z2+2 182 90 201 1 2 10
Z2+4 356 152 396 2 0 22
Z2+8 396 203 479 0 4 5
Z3+2 173 111 361 7 3 41
Z3+4 333 149 378 7 3 5
Z3+8 332 210 465 5 2 7