rigoletto@
Developer
In automobile terms you been riding on Empty too long.....
As long as your happy I am happy.
50K mine are retired.
1) somebody runs a cruise missile into my home when I'm away. Then maybe only a stick survives, and some valuable things are probably gone, and it takes a week or two to rebuild. (But then there will be other things that take longer to rebuild.)
2) somebody runs a cruise missile into my home when I'm at home. Then there is no problem at all. Anymore.

 www.baltimoresun.com
www.baltimoresun.com
I also have a stacker disk compression card. It still works, should I put that back in service?
DOUBLE YOUR DISK SPACE WITH COMPRESSION Stacker does it and you don’t even have to open your CPU
The hard disk on my vintage-1987 computer used to be a lot bigger. When it was new, it had an enormous 33 megabytes of open space. Today the same hard disk is cramped and claustrophobic, with a capacity of a measly 33 megabytes. It’s…
-rw-r--r-- 1 root wheel 36665 Feb 5 21:37 /usr/src/sys/dev/wds/wd7000.cThat is as far back as I have saved. I am saving an old Gateway server board with serverworks chipset and multiple PCI-X-133 slots.Then there is a bunch of beauties in PCI-X-64 design
Yes, the last ISA slot device I personally installed was an Intellicall controller card for a business job during Y2K meltdown work..I very much hope that your post about Stacker is meant as humor. If yes, you have succeeded, and I'm laughing.
bought my stacker compression card from 'Service Merchandise' bundled with a drive. I can't remember what drive.
I also could not find one retailer carrying it or the 4TB version also on the list: MD04ABA400VMD04ABA500V Toshiba 5TB 5400RPM
Yeah, I think I'll settle on WD Blue, since I don't exactly have the luxury to go big on this one.I don't know if this was such a great suggestion. There are plenty of enterprise 5 year SATA drives.
They do carry a heavy price premium.
On the other side of the coin I don't know that I would feel comfortable with the SMART that PMc is showing.
So, much of this comes down to what you want to spend to be happy.
")
Wow, that's INCREDIBLE, which says a lot about some Drives today. :OEvery hard drive I ever lost was a Maxxtor. My 19 year old 15GB samsung drive still works perfectly with no bad sectors.
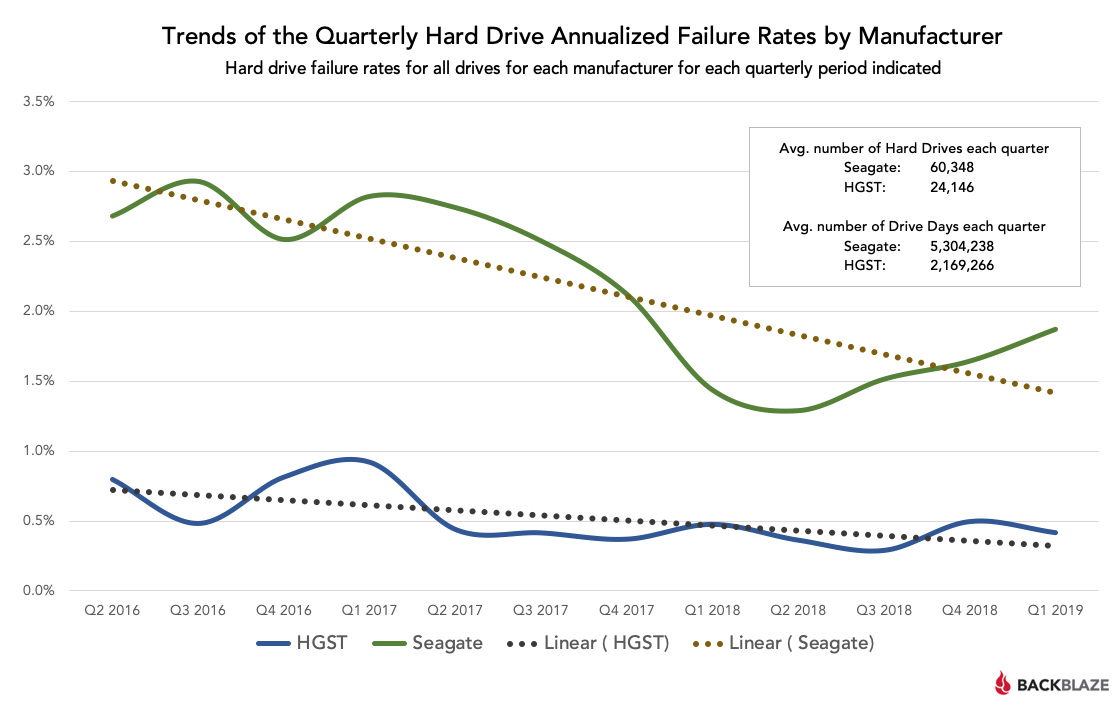
"I see", said the blind man.There is newer data from BackBlaze at https://www.backblaze.com/blog/backblaze-hard-drive-stats-q1-2019/
They are absolute heroes for publishing their failure statistics every quarter. It is the best openly available data for disk reliability, broken down by model and manufacturer. Unfortunately, the per-model data is not very useful for amateurs, since they only have good data after using a model for a considerable period, by which point that drive is often no longer available in the consumer market. They also only use nearline enterprise drives, while many amateurs use consumer drives. But one can easily draw conclusions that are generally predictive. My favorite graph is below (annual failure rate, lower is better). That pretty clearly tells you which disks to buy.
Thanks for that! I'll check out Backblaze more often. 
Wow, that's also impressive!Somewhere in the basement, I have two really good disks. One is a CDC/Imprimis/Seagate Wren, the other a Falcon (and I can't remember whether those were made by Maxtor or Fujitsu). They are both 1GB SCSI, and were bought in the late 80s or early 90s. Last time I booted those computers, they were both working; that was about 5 or 10 years ago.
Ok then...Yepp - the Hitachi rsp. HGST drives are IBM drives (the deskstar just as well), until the whole branch went to WD, and will most likely dissolve into the WD portfolio.
I for my part had an Hitachi and an original WD side by side in my desktop for quite a while, and there is a huge difference, and I would trust a half-wrecked Hitachi/HGST a lot more than a brand-new WD.
Something to consider. Thanks! Wow..... That was quite a post, and I loved every second of it!Not a flame, just a philosophical excursion about statistics.
The MTBF of disk drives is spec'ed by manufacturers as a million hours or more (sometimes 1.5 or 2 million for enterprise grade drives). Having been a user of many thousands of disk drives professionally, and not being able to share accurate statistics, my summary is that the disk manufacturers are sort of honest. The actual measured failure rates are perhaps half or two thirds of the specification. Now, some of those failures are probably not the fault of the drive (temporary overheating, too much vibration, flaws in power supplies), so this is not intended as criticism of Seagate, WD, Hitachi, Toshiba and friends. This is experience from drives that are installed in professional-grade enclosures (not computer cases but dedicated disk enclosures), with high-quality power supplies, and installed in well managed data centers. Customers who spend millions on their storage systems tend to not risk those systems due to inadequate environments, that would be dumb. So let's take a real-world MTBF (under professional conditions) of about 1/2 to 1 million hours:
Lesson #1: The MTBF of disk drives in good conditions is very high, about 50-100 years average life time = 1% to 2% annual failure rate, and therefore amateurs with just a handful of drives should very rarely see disk failures.
Quick observation: it is quite possibly to break a disk. Drop it (just a little bit) while it is spinning and seeking (laptop disks are better at that). Drop it from a foot height onto a granite table while powered down. Cook it (the 68 degrees above is bad news). Vibrate it all the time while writing. Connect it to a power supply whose 12V line can be 11V or 14V depending on the phase of the moon. Switch the 5V and 12V pins when making your own power cables (did that once). Some of these things will kill the drive outright, sometimes with smoke coming out; others will just reduce its lifetime (and data reliabilty) massively. But in most cases, these extreme mistakes don't happen: few people solder their own power cables, and most buy good quality cases and power supplies.
Lesson #2: But the MTBF as seen by amateurs is much below what large systems professionals see, because they don't have good environmental controls (temperature goes up and down), good enclosures, good power supplies. Still, it is not catastrophic; drives should not die like flies unless you abuse them.
But even in those professional settings, you have to exclude certain effects to get to these MTBF numbers. First is infant mortality: You have to bake in new drives for a week or two, and drives that fail during that time will be cheerfully replaced by the manufacturer, and does not count towards MTBF. Second is manufacturing problems that escape. We once had a whole delivery of drives (several thousand, single manufacturer single model) that had an infant mortality approaching several % per week, and that mortality kept on going for several months. This was a "manufacturing escape", due to a mistake a whole batch of drives had skipped the manufacturers quality control (oops), and happened to be low quality (double oops). The manufacturer cheerfully took the drives back, and (probably not cheerfully) gave us several M$ to compensate us for our troubles, and to make our customer less unhappy. This is human error, was acknowledged and corrected by the manufacturer, and should not be counted towards the MTBF number. Now, how would an individual amateur user who only bought 1 or 2 drives handled it? They don't have the metrics to demonstrate to the vendor that the problem is pervasive, they don't have hardware and software teams that can do autopsies on defective drives themselves, they don't have teams of lawyers to negotiate settlements.
Another case where drives had high failure rates was a system that was shipped to a city in a tropical country with really bad air quality, and stored there in a non airconditioned warehouse for half a year, unpacked. When it was finally turned on, many disks (about a third!) had electrical shorts, which were due to corrosion from sulfur in the atmosphere. Actually, our field service technicians ended up finding liquid drops of a corrosive liquid on the PC boards of the drives: condensation from the atmosphere, containing sulfuric acid. Again, because we were a big company we were able to diagnose what had gone wrong, and work with all stakeholders to come to an equitable solution. And again, this should not be counted towards the MTBF of the drive itself. But how would an amateur who lives in this city have handled it? He doesn't have ready access to air chemistry, he doesn't know how long the store had the drive on a shelf, and he doesn't have teams of lawyers to negotiate.
Lesson #3: For an amateur, systemic effects can mask the inherent good reliability of quality drives, and they may get lots of failures. Tough luck.
It is now widely known and reported that Seagate Barracuda drives (in particular the 1TB model) have had serious reliability problems. If you average those into Seagate's overall MTBF, then the result looks pretty bad for Seagate. I don't know whether Seagate ever had programs where the refunded those, extended the warranty, or had other arrangements with large users (I never worked with large quantities of that model professionally). Real-world example: Between a colleague of mine and me (he also worked on the disk subsystems for a large storage systems vendor), we went through 7 of these 1TB Barracuda drives at home (he had 5, I had 2), all of which died within a few years (in some cases before 2 years), and we know that our enclosures/power supplies/environment were at least OK. That failure rate is completely incompatible with the quoted 1M hours, and more points towards something in the range of a few 10K hours. He got some replaced under warranty, and we both threw the rest into the trash. But since I had been burned by that, I followed the fate of other Seagate drives later, and found that this problem did not repeat for other models.
Lesson #4: Some drive models just suck, and will die quickly. So quickly that even an amateur with a small number of drives (1...5) will have serious problems in a small number of years (1...5). But you can't extrapolate from a few bad models to all models in a series, and much less to a vendor.
And finally, look at the famous BackBlaze data. It is the best data set on disk quality that is freely accessible; there is better data out there, but it is not accessible. You clearly see that on average, Seagate is less reliable than the others, and that's not just one model, but systematic. But Seagate does not suck: their annual failure rate may be up to 2% and 3% for some models, but it is nowhere near the 30% or 50% that my friend and me saw, and that would be catastrophic.
In summary: The reliability of drives is complicated, and at the amateur level just not predictable. Not enough statistics. You may get very unlucky.
What can you do about this?
True story: About 25 years ago, I interviewed for a job at the storage systems research department of one of the largest and most prestigious computer companies in the world (two letters, not three). My host and future manager gave me a little tour of the computer room for fun, and showed me the main server the group used (in those days, a group of 15-20 people used a single large computer), and the two "big" RAID arrays connected to it (in those days, "big" meant dozens of disks). He then proceeded to pull a disk out of the running production machine, and hand it to me. I was flabbergasted. What this really demonstrated was: the guy was (and continues to be) very smart, and knew the reliability of his systems, and the value of impressing a person they might potential hire. I gave him back the disk, he put it back in, the disk array resilvered for a few more seconds, and everything was fine.
- Think about the value of your data. If it is worth nothing, and you will not feel bad if it is all gone suddenly, and your time for re-installing the system after a disk failure is worth nothing, then stop reading. All others, keep going.
- Use RAID. At the very minimum mirroring of two drives. If this is your only defense, it is not good enough, and a two-fault tolerant system is better or even necessary.
- If you are mirroring or RAIDing, consider using different drives (different models or even vendors) in a pair. Like that a systemic problem with a particular model is less likely to wipe you out. But that can be a bit tricky (different capacity, different performance, and in a RAID system the overall performance tends to be dominated by the slowest disk).
- Take backups. Like that a disk failure becomes an inconvenience (down for an hour or a day), and perhaps a small data loss (the data from the 23 hours may be gone), but not a catastrophe. Remember that RAID is not a panacea; it does not protect against correlated failure, nor is it 100% reliable, nor does it protect against human error.
- You have installed RAID already, right?
- Make a plan ahead of time: what will you do if a drive dies? Know the commands to resilver your RAID. Know where your backups are stored. Don't store the only documentation for how to restore from backup on the drive that you are backing up. Do a test run, regularly. A backup that has never been restored is not actually a backup, it might be a blank tape. Not a joke, happened to my wife's company once: after their disks died, they discovered that their clueless sys admin had set them up with RAID-0, and had dutifully written a blank tape every night, labelled it, and put it into the fireproof safe. Not fun.
- Your RAID is functioning well, you are monitoring disk health, and have set up an automatic monitoring system, right?
- Think about what other disasters you want to protect against (because disk failure is not a disaster, it is an expected operational situation). Are you worried about a fire or flood destroying the place where both your original disks and the backup are physically located? Are you worried about intruders stealing your hardware? Are you worried about someone snooping on you? A good backup system can deal with this, but at some cost.
- Inject a test fault into your RAID system (for fun, just pull a disk physically out), and watch it resilvering automatically, and your cellphone beeping because you got an e-mail from the monitoring system. That's when you can stop having anxiety attacks.
Quite engaging, and informative! Thanks for sharing your wealth of knowledge and experience! Thanks, PMc!Yepp - the Hitachi rsp. HGST drives are IBM drives (the deskstar just as well), until the whole branch went to WD, and will most likely dissolve into the WD portfolio.
I for my part had an Hitachi and an original WD side by side in my desktop for quite a while, and there is a huge difference, and I would trust a half-wrecked Hitachi/HGST a lot more than a brand-new WD.
Wait, did I already reply to your post? 
Ah, yes... The proverbial test.1 drive loss in 26 years, but not in server use, desktop use only. Drive was a Maxtor. Had mostly WD and some Seagates. Currently run desktop on Samsung SSDs, had those 3 years. Time will tell...
Yes, the famed litmus test, so-to-speak.I have WD reds (NAS) in my NAS - guessing that's what you mean. They are quiet (SATA) and supposed to be long lived. We shall see!
Just dive in and find out!! I have five WD reds in my ZFS server. They are 3 TB WD30EFRX. They are 6.5 years old. One failed a couple of years ago. Otherwise no problems (but I wish I had gone RAIDZ2, not RAIDZ1).I have WD reds (NAS) in my NAS - guessing that's what you mean. They are quiet (SATA) and supposed to be long lived. We shall see!