Hello,
I'm trying to build a PF active-active HA cluster which consists of 2 FreeBSD hosts (FW1 and FW2) with dynamic routing protocol (BGP in this case).
If there's a symmetrical flow (entering and returning through the same firewall) - everything is working fine, session is established and being replicated on the peer FW via pfsync0.
The problem I'm facing is with asymmetrical traffic flows like the below one:
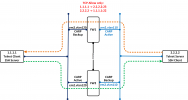
FW2 denies TCP segment with SYN+ACK flags set (2) sent from Server in response to the Client's TCP SYN request in (1).
The returned SYN+ACK segment (from Server to Client) is dropped by FW2, because it hasn't seen SYN-SENT session from FW1, yet.
TCP SYN+ACK segment comes just before the state is replicated from FW1 to FW2.
I've read that such kind of setup should be supported with PFSYNCv5 protocol and with "defer" option enabled on pfsync0 interface on both FWs, which will basically queue the initial SYN packet for a while until the SYN SENT state is replicated from FW1 to FW2. In my case I don't see any changes in the behavior with or without defer option enabled (ifconfig pfsync0 correctly displays whether or not defer is on)
I also tried to set "maxups" parameter to the minimum possible value=1 on pfsync0 interface on both FW1 and FW2, but this didn't help, either (tcpdump indicates that pfsync packets are sent much faster than before, which makes sense of course, because FWs are not waiting for several changes to be combined into a single pfsync packet)
Moreover I noticed that in FreeBSD's man pfsync(4) "defer" keyword is not mentioned anywhere unlike in OpenBSD's man pfsync (4) documentation and I assume there might be a reason for that? Can someone confirm whether or not this feature is working in FreeBSD?
Regards,
Plamen
I'm trying to build a PF active-active HA cluster which consists of 2 FreeBSD hosts (FW1 and FW2) with dynamic routing protocol (BGP in this case).
If there's a symmetrical flow (entering and returning through the same firewall) - everything is working fine, session is established and being replicated on the peer FW via pfsync0.
The problem I'm facing is with asymmetrical traffic flows like the below one:
Code:
(1) Client -------TCP SYN ---------> FW1 -------------------------> Server
|
pfsync
|
(2) Client <------------------------ FW2 <----- TCP SYN+ACK----- ServerFW2 denies TCP segment with SYN+ACK flags set (2) sent from Server in response to the Client's TCP SYN request in (1).
The returned SYN+ACK segment (from Server to Client) is dropped by FW2, because it hasn't seen SYN-SENT session from FW1, yet.
TCP SYN+ACK segment comes just before the state is replicated from FW1 to FW2.
I've read that such kind of setup should be supported with PFSYNCv5 protocol and with "defer" option enabled on pfsync0 interface on both FWs, which will basically queue the initial SYN packet for a while until the SYN SENT state is replicated from FW1 to FW2. In my case I don't see any changes in the behavior with or without defer option enabled (ifconfig pfsync0 correctly displays whether or not defer is on)
I also tried to set "maxups" parameter to the minimum possible value=1 on pfsync0 interface on both FW1 and FW2, but this didn't help, either (tcpdump indicates that pfsync packets are sent much faster than before, which makes sense of course, because FWs are not waiting for several changes to be combined into a single pfsync packet)
Moreover I noticed that in FreeBSD's man pfsync(4) "defer" keyword is not mentioned anywhere unlike in OpenBSD's man pfsync (4) documentation and I assume there might be a reason for that? Can someone confirm whether or not this feature is working in FreeBSD?
Regards,
Plamen