
I made a mistake and forgot to run
For some reason more than one file system is damaged, and each is on it's own virtual disk. Very unlucky for sure.
For my own sanity, I did check other VM's on that same hypervisor/data store and there is no indication of corruption. So that rules out a bad RAID controller.
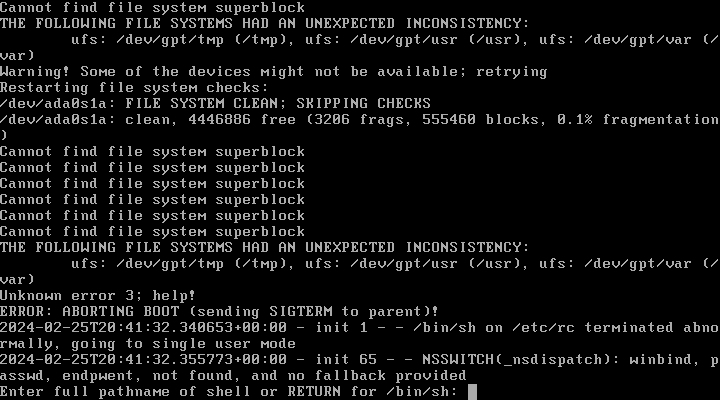
This is a virtual machine. I made a copy, put it on my local machine, fired up my local hypervisor, and booted off a 13.2-RELEASE ISO. I enter a live environment and start an SSH server so I can work on this comfortably without harming my original volumes.
I decide to work on trying to recover /usr since this contains the more interesting items (some configs that didn't get included in auto-backups).
First thing I tried is a
This fails with a segmentation fault
Full log and well as a version with the debug flag avaiable.
This happens no matter how many times I try.
If the filesystem is beyon repair, is it possible to do some sort of dump in the hopes that I can grab files or any text? At the end of the day, the more valuable data has already been restored from a backup on to a new system. I am also sure I have an old copy of these volume ssomewhere. For now the need/desire to search for those isn't as strong (yet), and at this moment I would rather spend the time/effort trying to recover stuff rather than searching.
fsck before doing a freebsd-update upgrade. Turns out the filesystem had some corruption and the vast amount of writes to it by freebsd-update made things even worse, so bad that it no longer mounts.For some reason more than one file system is damaged, and each is on it's own virtual disk. Very unlucky for sure.
For my own sanity, I did check other VM's on that same hypervisor/data store and there is no indication of corruption. So that rules out a bad RAID controller.
This is a virtual machine. I made a copy, put it on my local machine, fired up my local hypervisor, and booted off a 13.2-RELEASE ISO. I enter a live environment and start an SSH server so I can work on this comfortably without harming my original volumes.
Code:
root@:~ # gpart show -l
=> 63 20971457 ada0 MBR (10G)
63 20971377 1 (null) [active] (10G)
20971440 80 - free - (40K)
=> 34 20971453 da0 GPT (10G)
34 10485760 1 tmp (5.0G)
10485794 10485693 2 (null) (5.0G)
=> 40 41942960 da1 GPT (20G)
40 41942960 1 var (20G)
=> 40 41942960 da2 GPT (20G)
40 41942960 1 usr (20G)
=> 0 20971377 ada0s1 BSD (10G)
0 20971377 1 (null) (10G)
=> 63 20971457 diskid/DISK-00000000000000000001 MBR (10G)
63 20971377 1 (null) [active] (10G)
20971440 80 - free - (40K)
=> 0 20971377 diskid/DISK-00000000000000000001s1 BSD (10G)
0 20971377 1 (null) (10G)I decide to work on trying to recover /usr since this contains the more interesting items (some configs that didn't get included in auto-backups).
First thing I tried is a
fsck_ffs using an alternate superblock:
Code:
root@:~ # newfs -N /dev/da2p1
/dev/da2p1: 20480.0MB (41942960 sectors) block size 32768, fragment size 4096
using 33 cylinder groups of 626.22MB, 20039 blks, 80256 inodes.
super-block backups (for fsck_ffs -b #) at:
192, 1282688, 2565184, 3847680, 5130176, 6412672, 7695168, 8977664, 10260160, 11542656, 12825152, 14107648, 15390144,
16672640, 17955136, 19237632, 20520128, 21802624, 23085120, 24367616, 25650112, 26932608, 28215104, 29497600, 30780096,
32062592, 33345088, 34627584, 35910080, 37192576, 38475072, 39757568, 41040064This fails with a segmentation fault
Code:
Alternate super block location: 1282688
** /dev/da2p1
** Last Mounted on
** Phase 1 - Check Blocks and Sizes
BAD FILE SIZE I=2 OWNER=1414013498 MODE=35117
SIZE=7308609285986939493 MTIME=Oct 23 20:40 2021
CLEAR? yes
BAD FILE SIZE I=3 OWNER=979516216 MODE=64573
SIZE=4264967372109721914 MTIME=Jan 14 23:50 2001
CLEAR? yes
PARTIALLY ALLOCATED INODE I=4
CLEAR? yes
...
3052005 DUP I=731285
3052006 DUP I=731285
3052007 DUP I=731285
3212317 DUP I=731285
3212318 DUP I=731285
3212319 DUP I=731285
3696135 DUP I=731285
3853565 DUP I=731285
Segmentation faultFull log and well as a version with the debug flag avaiable.
This happens no matter how many times I try.
If the filesystem is beyon repair, is it possible to do some sort of dump in the hopes that I can grab files or any text? At the end of the day, the more valuable data has already been restored from a backup on to a new system. I am also sure I have an old copy of these volume ssomewhere. For now the need/desire to search for those isn't as strong (yet), and at this moment I would rather spend the time/effort trying to recover stuff rather than searching.
")