
D
Deleted member 70435
Guest
Virtual memory and address space
Consider the traditional distribution of process virtual memory on i386 (drawn from the picture by Matthew Dillon in pseudographics):
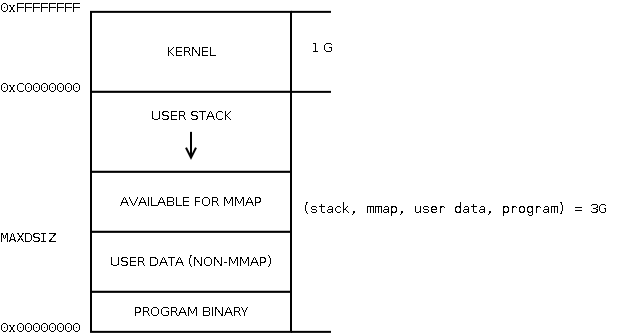
We are not interested in what is related to the process, but now we are interested in the part that is KERNEL. This part, which with the default compilation options on i386 is 1 GB, is common to all processes on the machine, and is present (displayed) in the address space each of them. Let's imagine that we have 10 processes running on an i386 machine with 40 GB of physical memory (No, that's not a typo. Imagine ). Then each process could use the full 2^32 = 4 GB of virtual memory available to it, and all 10 would fit in 40 GB of physical? No, because only 3 GB of address space is available to everyone - and if they eat up the memory available to them to the fullest, and the kernel does the same, there will be only 31 GB in total.
Where do these numbers come from? One page table entry, that is, describing 1 page of memory, occupies 4 bytes on the i386. Page size - 4 Kb. One level of the page table occupies again 1 page, i.e. 4 KB is 1024 entries, covering a total of 4 MB of virtual memory (then the next level of the page table is used). These 4 MB directory pages are what KVA_PAGES . In the case of PAE, the numbers are different, there is one element of 8 bytes, and the 1st level of the page catalog takes 4 pages, covering 2 MB of virtual memory - therefore, the KVA_PAGES are multiplied by 2. You can see more in the files pmap.h , param.h , vmparam.h in /sys/i386/include/ (or equivalent for another architecture), in the region of definitions with furious names like VADDR(KPTDI+NKPDE-1, NPTEPG-1) .
This approach of having kernel memory in the same process address space is not unique to FreeBSD, and is used in all modern operating systems, except that the default boundary may vary (Windows NT used to have 2 GB). It can be set when compiling the kernel, for example, options KVA_PAGES=384 will allocate 1.5 GB to the kernel, leaving processes only 2.5; is specified in units of 4 MB and must be a multiple of 16 MB (i.e. 256, 260, 264, etc.). From this it is clear that if the kernel has a large memory consumer, such as mdconfig -t malloc or ZFS, then the kernel address space may simply not be enough, even if there is still a mountain of free memory on the machine. On amd64, of course, the kernel was given 512 GB of space (these are just virtual addresses, why bother with them), so there will be no problems for this reason.
But these are just virtual addresses, and then we have real memory. Almost all the memory belonging to the kernel is not subject to swapping (imagine, for example, that when processing an interrupt from a network card, the nuclear memory lying in the swap was needed, and the swap is somewhere on a network drive), but there are still some exceptions, such as anonymous pipe buffers (which are sort | head , for example). In addition, application memory that has been told by mlock() is also prohibited from swapping (see memorylocked in ulimit ). All memory that cannot be swapped is visible in top as Wired . memory of the kernel, which we will be interested in further, is called kmem . Unfortunately, for the reasons stated above, it cannot be said that WIRED == KMEM . In other words, kmem is also virtual memory. Actually, kmem is not the only region of kernel memory (there are other vm_map whose sizes are controlled, for example, kern.ipc.maxpipekva , kern.nbuf , kern.nswbuf , etc.). It's just from this region that memory is allocated for UMA and malloc() , which will be discussed later. The kmem size is calculated using the following formula:
vm.kmem_size = min(max(max(VM_KMEM_SIZE, Physical_memory / VM_KMEM_SIZE_SCALE), VM_KMEM_SIZE_MIN), VM_KMEM_SIZE_MAX)
It looks scary, but the meaning is very simple. Consider, as an example, some Pervopen™ standing on a windowsill with 80 MB of RAM:
vm.kvm_size: 1073737728 1 GB minus 1 page: total kernel memory size
vm.kvm_free: 947908608 completely unallocated kernel memory addresses
vm.kmem_size_scale: 3
vm.kmem_size_max: 335544320 320 Mb: constant for autotuning
vm.kmem_size_min: 0
vm.kmem_size: 25165824 24 MB: Selected at boot max. kmem size
vm.kmem_map_size: 15175680 used in kmem
vm.kmem_map_free: 9539584 free in kmem
The first two parameters, although called KVM (kernel virtual memory), stand for kernel virtual address space (KVA). They count like this:
kvm_size = VM_MAX_KERNEL_ADDRESS — KERNBASE;
kvm_free = VM_MAX_KERNEL_ADDRESS — kernel_vm_end;
In BSD-style code, it is customary to use capital letters to denote constants that are set only during compilation (as well as macros) - these are the same 1 GB sizes discussed above. In the variable kernel_vm_end, the kernel stores the end of the used part of KVM (expanded if necessary). Now about the calculation of vm.kmem_size using an example. First, the available memory of the machine is divided by vm.kmem_size_scale , we get 24 MB. Further, kmem cannot be greater than vm.kmem_size_max and less than vm.kmem_size_min . In the example, vm.kmem_size_min is zero, in which case the VM_KMEM_SIZE constant is used at compile time (it is 12 MB for all platforms). Of course, the vm.kmem_size_min and vm.kmem_size_max settings are for autofitting (the same kernel/loader.conf can be loaded on different hardware), so vm.kmem_size can be set explicitly, in which case it will override vm.kmem_size_max . Although insurance is provided here too - it cannot be more than two sizes of physical memory. The nearest machine with amd64 reports that it has vm.kmem_size_scale is 1, and kmem_size is equal to almost all 4 GB of RAM (although much less is occupied in it).
You can read more about virtual memory in modern operating systems at http://www.intuit.ru/department/os/osintro/ (first chapters).
Slab UMA allocator and nuclear malloc
Why was such attention paid to kmem, as opposed to the rest of the kernel memory regions? Because it is it that is used for the usual malloc() and the new UMA slab allocator. Why was a new one needed? Let's consider how the memory looked at some point in the time of work with traditional allocators:
...->|<-- 40 bytes -->|<-- 97 bytes -->|<-- 50 bytes -->|<-- 20 bytes -->|<-- 80 bytes --- >|<-- 250 bytes -->|<-...
busy hole busy busy hole busy
Here at some point in time there were 6 objects, then 2 were released. Now, if a call to malloc(100) somewhere, then the allocator will not only be forced to leave unused holes from old objects in the amount of 177 bytes, but also sequentially go through all these free areas only to see that the requested 100 bytes will not fit there . Now imagine that the machine is constantly arriving at a speed of 100 Mbps packets of various sizes? The memory for them will very quickly become fragmented, with large losses and time spent on searching.
Of course, they began to fight this rather quickly - trees and other tricks instead of linear search, size rounding, different pools for objects of very different sizes, etc. But the main tool remained all sorts of caches in different subsystems, in fact, their own small allocators - in order to access the system one less. And when application programmers (including consumer subsystems in the kernel) start writing their own memory allocators, this is bad. And not by the fact that your allocator is likely to be worse, but by the fact that the interests of other subsystems were not taken into account - a lot of memory hung in reserved pools (we don’t use it now, but this memory would be useful to others), load patterns also did not take into account neighbors.
The most advanced solution, which is used in the general case even now - when slab allocators cannot be used - are allocators that allocate memory in blocks rounded up to 2 ^ n bytes. That is, for malloc(50) a piece of 64 bytes will be allocated, and for malloc(97) - a piece of 128 bytes. Blocks are grouped together in pools by size, which avoids problems with fragmentation and searches - at the cost of memory losses that can reach 50%. standard malloc(9) , which dates back to 4.4BSD, was done this way. Let's take a closer look at its interface.
MALLOC_DEFINE(M_NETGRAPH_HOOK, "netgraph_hook", "netgraph hook structures");
hook = malloc(sizeof(*hook), M_NETGRAPH_HOOK, M_NOWAIT | M_ZERO);
free(hook, M_NETGRAPH_HOOK);
If your malloc type is used somewhere else outside of one file, then in addition to MALLOC_DEFINE(M_FOO, "foo", "foo module mem"), will also need MALLOC_DECLARE(M_FOO) - see the definition of these macros: #define MALLOC_DEFINE(type, shortdesc, longdesc) \
struct malloc_type type[1] = { \
...
#define MALLOC_DECLARE(type) \
extern struct malloc_type type[1]
(in the old code there was also a macro MALLOC () in addition to the function, which immediately cast types, not so long ago it was cut out from everywhere)
As you can see, compared to the usual malloc() / free() in application applications, one more argument is specified here: the malloc type, defined somewhere at the beginning MALLOC_DEFINE() ; for malloc() and flags What is this type? It is designed for statistics. The allocator keeps track of how many objects, bytes, and what block sizes are currently allocated for each type. A system administrator can run the vmstat -m and see the following information:
- Type : subsystem name from MALLOC_DEFINE
- InUse : how many objects are currently allocated for this subsystem
- MemUse : how much memory this subsystem has used (always displayed in kilobytes rounded down)
- Requests : how many requests have been made to allocate objects for this subsystem since boot
- Size(s) : block sizes used for objects in this subsystem
$ vmstat -m
Type InUse MemUse HighUse Requests Size(s)
sigio 2 1K — 4 32
filedesc 92 31K — 256346 16,32,64,128,256,512,1024,2048,4096
kenv 93 7K — 94 16,32,64,128,4096
kqueue 4 6K — 298093 128,1024,4096
proc-args 47 3K — 881443 16,32,64,128,256
devbuf 233 5541K — 376 16,32,64,128,256,512,1024,2048,4096
CAM dev queue 1 1K — 1 64
It should be noted here that blocks are rounded up to 2^n only the page size, then rounding up to an integer number of pages. That is, a request of 10 KB will be allocated 12 KB, not 16.
call flags malloc() . M_ZERO is clear from the name - the allocated memory will be immediately filled with zeros. More important are two other mutually exclusive flags, one of which must be specified:
- M_NOWAIT - allocate memory from the currently available subset. If it's not there now, malloc() will return NULL. The situation is very likely, so it should always be handled (as opposed to malloc() in userland). This flag is required when called from an interrupt context - that is, for example, when processing a packet on the network.
- M_WAITOK - if there is not enough memory now, the calling thread stops and waits for it to appear. Therefore, this flag cannot be used in the context of an interrupt, but it can, for example, in the context of a syscall - that is, upon request from the user process. With this flag, malloc() will never return NULL, but will always give out memory (may wait a very long time) - if there is not enough memory at all, the system says panic: kmem_malloc( size ): kmem_map too small
It should be noted that this panic, as a rule, does not occur in the subsystem that ate all the memory. A typical example from life: a small router falls into such a panic in UFS with a request of 16384 bytes - this is some process that wants to read something from disk, and malloc (16384, ..., M_WAITOK) - memory no more in kmem, everything, the crust is preserved. After the reboot, we do vmstat -m -M /var/crash/vmcore.1 and see that NAT based on libalias ate - it just broke off with M_NOWAIT in getting more memory, but the system still lived.
Back in the late 80s, research began on special allocators designed for individual subsystems. They performed better than the general allocator, but suffered from the shortcomings indicated at the beginning of this section - poor interaction with other subsystems. The most important conclusion from the research is: "...a customized segregated-storage allocator - one that has a priori knowledge of the most common allocation sizes - is usually optimal in both space and time".
And in 1994, based on this conclusion, Jeff Bonwick from Sun Microsystems came up with (and implemented in Solaris) the so-called Slab Allocator (the name refers to a chocolate bar that is divided into slices). The essence of the idea: each subsystem that uses many objects of the same type (and therefore the same size), instead of establishing its own caches, is registered in a slab-allocator. And he himself manages the size of the caches, based on the total amount of free memory. Why caches? Because the allocator, when registered, takes the functions of the constructor and destructor of the object, and returns an already initialized object when allocated. It can initialize a number of them in advance, and with free(), the object can only be partially deinitialized, simply returning to the cache and being immediately ready for the next allocation.
The "tile" that normally makes up a page of virtual memory is broken down into objects that are densely packed. For example, if the object size is 72 bytes, they fit 58 pieces on one page, and only a "tail" of 64 bytes remains unused - only 1.5% of the volume is wasted. Usually in this tail there is a slab header with a bitmap which of the objects are free, which are allocated:
<---------------- Page (UMA_SLAB_SIZE) ------------------>
___________________________________________________________
| _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ ___________ |
||i||i||i||i||i||i||i||i||i||i||i||i||i||i||i| |slab header|| i == item
||_||_||_||_||_||_||_||_||_||_||_||_||_||_||_| |___________||
|___________________________________________________________|
The FreeBSD implementation of slab is called UMA (Universal Memory Allocator) and is documented in zone(9) . The consumer calls uma_zcreate() to create a zone - a collection of objects of the same type / size, from which allocations will occur (it is a cache). From a system administrator's point of view, the most important thing is that a zone can be set to a limit using uma_zone_set_max() . The zone will not grow beyond the limit, and if the allocation was done using M_WAITOK in syscall for a user process, then it will hang in top in the keglim (in previous versions it was called zoneli ) until there are free elements.
The system administrator can see the current state of the UMA in vmstat -z :
| $ vmstat -z ITEM SIZE LIMIT USED FREE REQUESTS FAILURES A Kegs: 128, 0, 90, 0, 90, 0 A Zone: 480, 0, 90, 6, 90, 0 A Slabs: 64, 0, 514, 17, 2549, 0 A RCntSlabs: 104, 0, 117, 31, 134, 0 A Hash: 128, 0, 5, 25, 7, 0 16: 16, 0, 2239, 400, 82002734, 0 32: 32, 0, 688, 442, 78043255, 0 64: 64, 0, 2676, 1100, 1368912, 0 128: 128, 0, 2074, 656, 1953603, 0 256: 256, 0, 706, 329, 5848258, 0 512: 512, 0, 100, 100, 3069552, 0 1024: 1024, 0, 49, 39, 327074, 0 2048: 2048, 0, 294, 26, 623, 0 4096: 4096, 0, 127, 38, 481418, 0 socket: 416, 3078, 62, 109, 999707, 0 | Fields meaning:
|
As the Facebook developers remarked about universality: "If it isn't general purpose, it isn't good enough." We at FreeBSD love to develop universal things - GEOM, netgraph and much more ... And it was the new universal allocator for user applications jemalloc that was taken by the developers of Facebook and Firefox 3. For more information on how things are now on the front of scalable allocators, you can read in their note http://www.facebook.com/note.php?note_id=480222803919
In the example, you can see why UMA is called universal - because it uses its zones even for its own structures, and besides, malloc () is now implemented on top of the same UMA - zone names from "16" to "4096". The meticulous reader, however, will notice that here the block sizes are only 4096 inclusive, and more can be allocated - and it will be right. Larger objects are allocated by the uma_large_malloc() - and, unfortunately, they are not taken into account in the general zone statistics. It can be found that the result
vmstat -m | sed -E 's/.* ([0-9]+)K.*/\1/g' | awk '{s+=$1}END{print s}' does not match with vmstat -z | awk -F'[:,]' '/^[0-9]+:/ {s += $2*($4+$5)} END {print s}' exactly because of this reason. However, even if you sum vmstat -m and all other zones, it will still be an inaccurate kmem size due to page alignments, UMA losses due to page tails, and so on. Therefore, on a live system it is more convenient to use sysctl vm.kmem_map_size vm.kmem_map_free , leaving awk for post-mortem analysis of crusts.By the way, returning to the example with the panicked little router: if in the kernel libalias not malloc() , but uma_zalloc() (it takes 2 arguments - the zone and the same flags M_NOWAIT/M_WAITOK ), then, firstly, the size of the element would not be rounded would be up to 128 bytes, and more translations would fit into the same memory. Secondly, it would be possible to set a limit for this zone and avoid uncontrolled capture of memory by libalias in general.
For more information on slab allocators, see "The Slab Allocator: An Object-Caching Kernel Memory Allocator" by Jeff Bonwick, Sun Microsystems (available online in PDF), and man uma (aka man zone ).
Network subsystem memory: mbuf
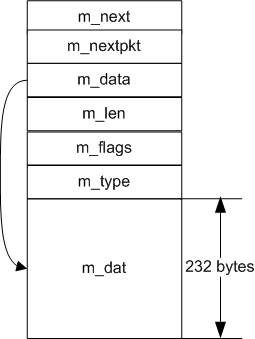
Rice. 1. Structure mbuf (size calculated for 32-bit architectures)
So, it was described that memory fragmentation has a bad effect on the performance of the allocator, that this can be dealt with either at the cost of memory loss due to rounding up the size, or using slab allocators when there are many objects of the same type / size. Now let's see what happens in the network subsystem? Not only do incoming packets vary greatly in size, there is a much more serious problem: during the life of a packet, its size changes - headers are added and removed, it may be necessary to split user data into segments, collect them back when reading into a large user process buffer, etc.
To solve all these problems that existed then, in the 80s, at once, BSD introduced the concept of mbuf (memory buffer) - a data structure of a small fixed size. These buffers were combined into linked lists, and the data of the packet, thus, turned out to be spread over a chain of several mbufs. Since the size is fixed, there is no problem with the allocator, which was an add-on to the standard one (in our time, of course, they are allocated by the UMA). Since this is a linked list, adding another mbuf to its head with a lower level header (IP or L2) is no problem.
Physically, mbuf, as can be seen from Figure 1, is a buffer of a certain size, at the beginning of which there is a fixed header. Fields (not changed for many years) are used to link several mbufs in lists, indicate the type of content, flags, the actual length of the data contained, and a pointer to its beginning. It is clear that, for example, to "cut off" the IP header, you can simply increase the data start pointer by 20 bytes, and reduce the content length by 20 bytes - then the data at the beginning of the buffer will become, as it were, free, without any movement of the packet bytes in memory ( This is a relatively costly operation. And to remove data from the end, it is generally enough just to reduce the length without touching the pointer.
Historically, the size of one mbuf was 128 bytes including this fixed header. It was used in the network subsystem for almost everything - addresses, paths, routing table entries ... Therefore, the name is universal, and not just about packets. Then all these complications of the "all-in-one" code were cleaned up, and from the existing types, only those related to sockets remained (in addition to the packet data itself, this is, for example, OOB data or ancillary data in struct cmsghdr ). Also, over the years, new fields have gradually been added to the variable part of mbuf, and so as of FreeBSD 4, the size of mbuf (the MSIZE in param.h ) is already 256 bytes.