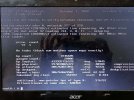
My system is unable (causes panic while booting) to boot because apparently zpool shows some corruption in zroot
Here's the output
How do I fix this error?
I tried
PS : System boots into multiuser mode just fine when
Here's the output
Code:
zpool status -v
pool: zroot
state: ONLINE
status: One or more devices has experienced an error resulting in data corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8008-8A
scan: scrub repaired 8B in 00:20:19 with 2 errors on Sun Dec 11 17:51:59 2822
config:
NAME STATE
zroot ONLINE
ada8p3.eli ONLINE
READ WRITE CKSUM
0 0 0
0 0 4
errors: Permanent errors have been detected in the following files:
zroot/tmp: <0x3>How do I fix this error?
I tried
zpool scrub zroot multiple times now, but that hasn't helpedPS : System boots into multiuser mode just fine when
zfs_enable="YES" is commented out of rc.conf. But obviously not of any use without the underlying file system.
Last edited by a moderator: