Hi,
We have a strange problem with one of our web/jails servers. Everything was working fine through 12.x releases, but immediately after we upgraded from 12.3 to 13.1 server started "losing" RAM, couple GB per day.
Server is Supermicro SYS-6019P-MTR, with 128 GB RAM, ZFS ... Nothing extra in the /boot/loader.conf or /etc/sysctl.conf.
After two weeks, top, systat and vmstat show that system has 24 GB of RAM (when we calculate memory usage). But sysctl hw.physmem shows 128 GB.
Did anyone have experience with something similar?
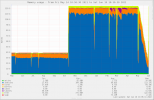
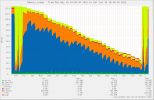
Here is munin graphs ... RAM upgrade was in the mid October, a then in May upgrade from 12.3 to 13.1.
We have a strange problem with one of our web/jails servers. Everything was working fine through 12.x releases, but immediately after we upgraded from 12.3 to 13.1 server started "losing" RAM, couple GB per day.
Server is Supermicro SYS-6019P-MTR, with 128 GB RAM, ZFS ... Nothing extra in the /boot/loader.conf or /etc/sysctl.conf.
After two weeks, top, systat and vmstat show that system has 24 GB of RAM (when we calculate memory usage). But sysctl hw.physmem shows 128 GB.
Did anyone have experience with something similar?
Here is munin graphs ... RAM upgrade was in the mid October, a then in May upgrade from 12.3 to 13.1.