Preface
I'm posting this in the Networking forum, though it could possibly be more valid in the Firewall forum. Moderators please move if required.
Executive Summary
I'm having an issue with very poor performance in one particular direction through a Wireguard tunnel between two FreeBSD 13.1 hosts, which manifests as generally poor performance for all real traffic going through these tunnels. My setup is (very excessively) complex however, so explaining what's going on requires some context.
Setup Context
I'm using a pair of redundant FreeBSD boxes to provide me a "virtual point-of-presence" for servers in my house out of a colocation provider. I'm accomplishing this by having a /28 block routed to my Colocation endpoint router ("rr1"), a set of Wireguard tunnels between my Home endpoint router ("dcr1") and the Colocation endpoint router, and pf NAT in the Home endpoint router. The end result is that I have a set of public IPs on the Internet that, to the outside, appear to be in a Colocation, but are actually terminating at the server rack in my house where the physical servers lie.
I have 3 diagrams attached to explain the setup in more detail.
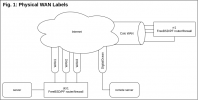
Figure 1 ("WAN+VPN Flow - Fig1.png") shows how the "physical" links are set up. My servers connect through dcr1 as their gateway. On dcr1 are 3 WAN connections to the Internet. At the colocation provider, rr1 is a standalone box with a single physical connection but multiple logical connections. Finally, I have a remote server which is a VPS in Digital Ocean.
The WAN connections in Figure 1 have the following configurations:
* WAN1: DOCSIS, 1000 Mbps down, 50 Mbps up
* WAN2: Fixed LTE, 25 Mbps down, 10 Mbps up
* WAN3: DSL, 25 Mbps down, 5 Mbps up
* Colo WAN: Ethernet to provider, 100 Mbps down, 100 Mbps up
* DigitalOcean: Ethernet to provider, >1000 Mbps down, >1000 Mbps up
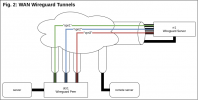
Figure 2 ("WAN+VPN Flow - Fig2.png") shows how the Wireguard tunnels are set up over the above WANs. On rr1 I have 3 discrete Wireguard Server processes running, on 3 different ports and 3 different public IP addresses. On dcr1, I have system-level routes to forward traffic to each of the 3 different rr1 IPs each out of a different WAN. The Wireguard Clients initiate the connections to the Wireguard Servers on the different port/IP combinations, such that the Wireguard tunnel vpn1 goes out of WAN1, vpn2 goes out WAN2, and vpn3 goes out WAN3.
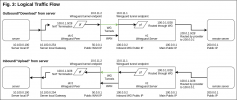
Figure 3 ("WAN+VPN Flow - Fig2.png") shows the basic traffic flow in both directions from the perspective of my house. The IPs shown are examples but RFC1918 is RFC1918 and public is public. This shows how traffic is routed in and out over the Wireguard tunnels (only vpn1 shown for simplicity). On the rr1 side I am leveraging pf with sets of route-to and reply-to rules to direct the traffic over the VPN links but traffic is otherwise unencumbered. On the dcr1 side I am leveraging pf as a full stateful firewall with NAT translation terminating the routed public IP block.
Hopefully this makes the setup clear to help in understanding the trouble I'm having.
Primary Problem Description
When initiating outbound connections ("downloads") from the servers in my network, NAT'd out the public IPs routed over the Wireguard tunnels, I'm experiencing very low performance, at least one or two orders of magnitude lower than the aforementioned connection speeds would suggest. For instance, downloading a test file from remote server to server via the Wireguard tunnels results in speeds around 400 KB/s (~3 Mbps); in contrast, downloading the same testfile over WAN1 directly results in speeds in excess of 50 MB/s (~400 Mbps). In the other direction, downloading a test file from server to remote server over the Wireguard tunnels, my speeds are within 80% of the expected bandwidth of the links in question, around 5 MB/s (~40 Mbps) compared to the expected ~50 Mbps.
Simplest Test
To try to determine exactly what is happening vis-a-vis the Wireguard tunnels themselves, I set up a set of iperf3 tests directly across the Wireguard links to evaluate their performance. What I found was a very strange asymmetry in performance here that might possibly explain the above issues over the full configuration.
To test this, I ran 4 separate test configurations over the WAN1/vpn1 link, with the client-side results of a 10s test shown:
*
*
*
*
This seems to be showing the following:
1. The speed when going "up" through the WAN1 (~50 Mbps connection due to dcr1 side) tunnel is very close to the expected speed, >80% of expected, regardless of which side is the iperf3 server or client.
2. The speed when going "down" through the WAN1 (~100 Mbps connection due to rr1 side) tunnel is very close to the expected speed, >75% of expected, when rr1 is the iperf3 client and dcr1 is the iperf3 server.
3. The speed when going "down" through the WAN1 (~100 Mbps connection due to rr1 side) tunnel is utterly abysmal, <0.4% of expected, when rr1 is the iperf3 client and dcr1 is the iperf3 server.
This bizarre result has me convinced that the general performance problem I described has something to do with this strange behavior directly over the Wireguard tunnel, but I'm not 100% certain.
pf Firewall Configuration/Context
The configuration of
In terms of Wireguard, both endpoints have a quick permit rule to ensure that the Wireguard VPNs can connect as expected, do not hit any (later) routing, etc.; e.g.:
To do routing out the tunnels, I have rules like the following, created into anchors in
I also have sets of `reply-to` rules to ensure that traffic passes back out the same way it came in. The "peer_vpnX" variables map to the 10.0.1X.Y addresses shown above (depending on the side), and the
Note that no performance change is observed regardless of which VPN is active; if I test with only vpn1 active, i.e.
Wireguard Tweaks Attempted
I've made multiple attempts to tweak the Wireguard tunnels, mostly centered around the MTUs. By running a full suite of nr-wg-mtu-finder tests, I was able to find that the optimal MTUs, to give the above test results, were 1500 on the Wireguard server side (rr1) and 1392 on the Wireguard client side (dcr1). There might be further efficiencies if I drop the Wireguard server side (rr1) MTU, but if I do so, I run into problems passing large packets (e.g. SSL), so that side must remain 1500.
I know it's possible that there is some inefficiencies with the larger-than-wire-size MTU on the Wireguard server side, but it doesn't seem like enough to explain the abysmal performance in only one particular test direction (i.e. the 2rd test above), nor the general drop only in one direction (and in the direction of *higher* outside bandwidth).
And my real world download tests mentioned at the very start do not seem to change regardless of these MTU changes; it always maxes out around 400 KB/s download despite expecting at least a few MB/s.
Trying to figure out what is going on here
With all that context out of the way, basically, my question is this: what can I do to try to fix things here? Does anyone have any ideas as to the cause, or things I could try to help improve the performance here? At this point I've spent several months fighting with this problem, tweaking so many things that I've lost track of it all, but I hope that what I have outlined above is enough of a starting point to get some feedback.
I'm posting this in the Networking forum, though it could possibly be more valid in the Firewall forum. Moderators please move if required.
Executive Summary
I'm having an issue with very poor performance in one particular direction through a Wireguard tunnel between two FreeBSD 13.1 hosts, which manifests as generally poor performance for all real traffic going through these tunnels. My setup is (very excessively) complex however, so explaining what's going on requires some context.
Setup Context
I'm using a pair of redundant FreeBSD boxes to provide me a "virtual point-of-presence" for servers in my house out of a colocation provider. I'm accomplishing this by having a /28 block routed to my Colocation endpoint router ("rr1"), a set of Wireguard tunnels between my Home endpoint router ("dcr1") and the Colocation endpoint router, and pf NAT in the Home endpoint router. The end result is that I have a set of public IPs on the Internet that, to the outside, appear to be in a Colocation, but are actually terminating at the server rack in my house where the physical servers lie.
I have 3 diagrams attached to explain the setup in more detail.
Figure 1 ("WAN+VPN Flow - Fig1.png") shows how the "physical" links are set up. My servers connect through dcr1 as their gateway. On dcr1 are 3 WAN connections to the Internet. At the colocation provider, rr1 is a standalone box with a single physical connection but multiple logical connections. Finally, I have a remote server which is a VPS in Digital Ocean.
The WAN connections in Figure 1 have the following configurations:
* WAN1: DOCSIS, 1000 Mbps down, 50 Mbps up
* WAN2: Fixed LTE, 25 Mbps down, 10 Mbps up
* WAN3: DSL, 25 Mbps down, 5 Mbps up
* Colo WAN: Ethernet to provider, 100 Mbps down, 100 Mbps up
* DigitalOcean: Ethernet to provider, >1000 Mbps down, >1000 Mbps up
Figure 2 ("WAN+VPN Flow - Fig2.png") shows how the Wireguard tunnels are set up over the above WANs. On rr1 I have 3 discrete Wireguard Server processes running, on 3 different ports and 3 different public IP addresses. On dcr1, I have system-level routes to forward traffic to each of the 3 different rr1 IPs each out of a different WAN. The Wireguard Clients initiate the connections to the Wireguard Servers on the different port/IP combinations, such that the Wireguard tunnel vpn1 goes out of WAN1, vpn2 goes out WAN2, and vpn3 goes out WAN3.
Figure 3 ("WAN+VPN Flow - Fig2.png") shows the basic traffic flow in both directions from the perspective of my house. The IPs shown are examples but RFC1918 is RFC1918 and public is public. This shows how traffic is routed in and out over the Wireguard tunnels (only vpn1 shown for simplicity). On the rr1 side I am leveraging pf with sets of route-to and reply-to rules to direct the traffic over the VPN links but traffic is otherwise unencumbered. On the dcr1 side I am leveraging pf as a full stateful firewall with NAT translation terminating the routed public IP block.
Hopefully this makes the setup clear to help in understanding the trouble I'm having.
Primary Problem Description
When initiating outbound connections ("downloads") from the servers in my network, NAT'd out the public IPs routed over the Wireguard tunnels, I'm experiencing very low performance, at least one or two orders of magnitude lower than the aforementioned connection speeds would suggest. For instance, downloading a test file from remote server to server via the Wireguard tunnels results in speeds around 400 KB/s (~3 Mbps); in contrast, downloading the same testfile over WAN1 directly results in speeds in excess of 50 MB/s (~400 Mbps). In the other direction, downloading a test file from server to remote server over the Wireguard tunnels, my speeds are within 80% of the expected bandwidth of the links in question, around 5 MB/s (~40 Mbps) compared to the expected ~50 Mbps.
Simplest Test
To try to determine exactly what is happening vis-a-vis the Wireguard tunnels themselves, I set up a set of iperf3 tests directly across the Wireguard links to evaluate their performance. What I found was a very strange asymmetry in performance here that might possibly explain the above issues over the full configuration.
To test this, I ran 4 separate test configurations over the WAN1/vpn1 link, with the client-side results of a 10s test shown:
*
iperf -c 10.0.11.1 on dcr1, iperf -s -B 10.0.11.1 on rr1: testing "upload" from dcr1 to rr1 with dcr1 as client
Code:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 56.0 MBytes 47.0 Mbits/sec 49 sender
[ 5] 0.00-10.07 sec 55.9 MBytes 46.5 Mbits/sec receiver*
iperf -c 10.0.11.1 -R on dcr1, iperf -s -B 10.0.11.1 on rr1: testing "download" from rr1 to dcr1 with dcr1 as client
Code:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.01 sec 69.3 KBytes 56.7 Kbits/sec 59 sender
[ 5] 0.00-10.00 sec 39.1 KBytes 32.0 Kbits/sec receiver*
iperf -s -B 10.0.11.2 on dcr1, iperf -c 10.0.11.2 on rr1: testing "download" from rr1 to dcr1 with rr1 as client
Code:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 92.5 MBytes 77.6 Mbits/sec 39 sender
[ 5] 0.00-10.02 sec 91.7 MBytes 76.7 Mbits/sec receiver*
iperf -s -B 10.0.11.2 on dcr1, iperf -c 10.0.11.2 -R on rr1; testing "upload" from dcr1 to rr1 with rr1 as client
Code:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.01 sec 51.9 MBytes 43.5 Mbits/sec 123 sender
[ 5] 0.00-10.00 sec 51.1 MBytes 42.9 Mbits/sec receiverThis seems to be showing the following:
1. The speed when going "up" through the WAN1 (~50 Mbps connection due to dcr1 side) tunnel is very close to the expected speed, >80% of expected, regardless of which side is the iperf3 server or client.
2. The speed when going "down" through the WAN1 (~100 Mbps connection due to rr1 side) tunnel is very close to the expected speed, >75% of expected, when rr1 is the iperf3 client and dcr1 is the iperf3 server.
3. The speed when going "down" through the WAN1 (~100 Mbps connection due to rr1 side) tunnel is utterly abysmal, <0.4% of expected, when rr1 is the iperf3 client and dcr1 is the iperf3 server.
This bizarre result has me convinced that the general performance problem I described has something to do with this strange behavior directly over the Wireguard tunnel, but I'm not 100% certain.
pf Firewall Configuration/Context
The configuration of
pf in my setup is quite complex for reasons unrelated to this WAN setup (I have a very large home server network setup, multiple public facing services, etc.), so while I might be able to blame it for some performance drop, given that the above tests that should completely bypass it, I don't think this is the underlying issue.In terms of Wireguard, both endpoints have a quick permit rule to ensure that the Wireguard VPNs can connect as expected, do not hit any (later) routing, etc.; e.g.:
Code:
dcr1 $ grep '5511' /etc/pf.conf
pass out quick proto { tcp udp } from (self) to any port { 5511 5512 5513 } keep state label "Allow all outbound Wireguard traffic to rrX"
Code:
rr1 $ grep '5511' /etc/pf.conf
pass in quick on lagg0 proto { tcp udp } from any to (self) port { 5511 5512 5513 } keep state label "Allow all inbound Wireguard traffic to rrX"To do routing out the tunnels, I have rules like the following, created into anchors in
pf using ifstated:
Code:
dcr1 $ sudo pfctl -s rules -a prod_server-vpn-lb
pass in quick on vlan100 route-to { (vpn1 10.0.11.1), (vpn2 10.0.12.1), (vpn3 10.0.13.1) } round-robin inet from <net_PROD_VM> to ! <rfc1918> flags S/SA keep state label "Load-balanced VPN outbound, PROD_VM"
Code:
rr1 $ sudo pfctl -s rules -a vpn-lb
pass in quick on lagg0 route-to { (vpn1 10.0.11.2), (vpn2 10.0.12.2), (vpn3 10.0.13.2) } round-robin inet from any to <net_ROUTED> flags S/SA keep state label "Pass routed /28 over tunnels (vpn1+2+3)"I also have sets of `reply-to` rules to ensure that traffic passes back out the same way it came in. The "peer_vpnX" variables map to the 10.0.1X.Y addresses shown above (depending on the side), and the
tag "vpnincoming" on the dcr1 side is used in later filter rules.
Code:
dcr1 $ grep 'reply-to ( $if_vpn' /etc/pf.conf
pass in quick on $if_vpn1 reply-to ( $if_vpn1 $peer_vpn1 ) inet from any to any tag "vpnincoming" keep state label "Allow rule tagging incoming traffic from vpn1"
pass in quick on $if_vpn2 reply-to ( $if_vpn2 $peer_vpn2 ) inet from any to any tag "vpnincoming" keep state label "Allow rule tagging incoming traffic from vpn2"
pass in quick on $if_vpn3 reply-to ( $if_vpn3 $peer_vpn3 ) inet from any to any tag "vpnincoming" keep state label "Allow rule tagging incoming traffic from vpn3"
Code:
rr1 $ grep reply-to /etc/pf.conf
pass in quick on $if_vpn1 reply-to ( $if_vpn1 $peer_vpn1 ) inet from any to any keep state label "Allow all traffic from Wireguard vpn1 peer"
pass in quick on $if_vpn2 reply-to ( $if_vpn2 $peer_vpn2 ) inet from any to any keep state label "Allow all traffic from Wireguard vpn2 peer"
pass in quick on $if_vpn3 reply-to ( $if_vpn3 $peer_vpn3 ) inet from any to any keep state label "Allow all traffic from Wireguard vpn3 peer"Note that no performance change is observed regardless of which VPN is active; if I test with only vpn1 active, i.e.
... route-to { (vpn1 10.0.11.1) } inet ..., the performance is the same as if all 3 are active, which I would expect since the routing is on a TCP connection level.Wireguard Tweaks Attempted
I've made multiple attempts to tweak the Wireguard tunnels, mostly centered around the MTUs. By running a full suite of nr-wg-mtu-finder tests, I was able to find that the optimal MTUs, to give the above test results, were 1500 on the Wireguard server side (rr1) and 1392 on the Wireguard client side (dcr1). There might be further efficiencies if I drop the Wireguard server side (rr1) MTU, but if I do so, I run into problems passing large packets (e.g. SSL), so that side must remain 1500.
I know it's possible that there is some inefficiencies with the larger-than-wire-size MTU on the Wireguard server side, but it doesn't seem like enough to explain the abysmal performance in only one particular test direction (i.e. the 2rd test above), nor the general drop only in one direction (and in the direction of *higher* outside bandwidth).
And my real world download tests mentioned at the very start do not seem to change regardless of these MTU changes; it always maxes out around 400 KB/s download despite expecting at least a few MB/s.
Trying to figure out what is going on here
With all that context out of the way, basically, my question is this: what can I do to try to fix things here? Does anyone have any ideas as to the cause, or things I could try to help improve the performance here? At this point I've spent several months fighting with this problem, tweaking so many things that I've lost track of it all, but I hope that what I have outlined above is enough of a starting point to get some feedback.