Hello everybody,
I am not an IT professional but as I can understand I do appreciate the FreeBSD os, zfs, bhyve and all stuff and I decided to learn more about these, So I built a customized computer which I consider appropriate for using with FreeBSD and ZFS, with the following configuration:
- processor AMD Ryzen 5 3400G 3.76GHz
- motherboard Asus Tuf Gaming B550-plus AMD B550 socket AM4
- ram Corsair Vengeance LPX Black DIMM DDR4 32 GB (2x16GB) CL15 3200Mbs
- LSI 9300-8i PCI E 3.0 12Gbps HBA
- two DELL 600 GB 10k SAS ISE 12GBps
- two 1TB HDD Seagate SAS 10k 2.5''
- cords SAS Controller SAS HD SFF 8643
- an extra Gigabit Ethernet card 1000/100/10 Mbps
Here is my ZFS configuration
zpool0
mirror-0
da2p4
da3p4
zpool1
mirror-0
da0
da1
(da0, da1 correspond to the 1 TB disks; da2, da3 correspond to the 600GB disks)
At the installation time I created zpool0. the second zpool was created thereafter with zpool create ...
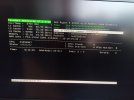
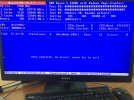
I installed FreeBSD 13.2 stable version using ZFS, the desired packages, I installed Windows 10 vm with bhyve, but I experienced frequent kernel panic crashes and after a few such events I run into "Mounting from ZFS: ... failed with error 5". I thought that I made something wrong with software installation so I reinstalled everything. After a few such cycles, I considered the possibility of a hardware problem and after the last mounting zfs issue I reboot the computer with an usb install media and in the shell, after importing the zpool i run
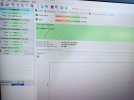
then in the output of
the recommended action was to perform zpool0 clear... or to replace two disks (da2, da3).
After
everything looked normal , but at reboot the mount zfs issue persisted.
So I sent the computer back to the hardware technicians who built it, but the problem is that in my hometown it seems that nobody have even a clue how to build a non-windows computer and about zfs, well, they don't even heard about it.
1. Is it possible that my computer configuration be the cause of the problems?
2. Now I cannot boot and login into my computer. Is it possible to check the /var/log/messages from the shell of the usb installer?
3. Is HD tune pro 5.70 a suitable tool for checking for I/O HDD errors if the disks are working under FreeBSD (this tool is used by the hardware firm to test the computer) ?
4. Can I install the package smartmontools from the shell of the usb install media in order to use smartcli command to check the disks ?
5. Any other guidance would be very much appreciated
I am not an IT professional but as I can understand I do appreciate the FreeBSD os, zfs, bhyve and all stuff and I decided to learn more about these, So I built a customized computer which I consider appropriate for using with FreeBSD and ZFS, with the following configuration:
- processor AMD Ryzen 5 3400G 3.76GHz
- motherboard Asus Tuf Gaming B550-plus AMD B550 socket AM4
- ram Corsair Vengeance LPX Black DIMM DDR4 32 GB (2x16GB) CL15 3200Mbs
- LSI 9300-8i PCI E 3.0 12Gbps HBA
- two DELL 600 GB 10k SAS ISE 12GBps
- two 1TB HDD Seagate SAS 10k 2.5''
- cords SAS Controller SAS HD SFF 8643
- an extra Gigabit Ethernet card 1000/100/10 Mbps
Here is my ZFS configuration
zpool0
mirror-0
da2p4
da3p4
zpool1
mirror-0
da0
da1
(da0, da1 correspond to the 1 TB disks; da2, da3 correspond to the 600GB disks)
At the installation time I created zpool0. the second zpool was created thereafter with zpool create ...
I installed FreeBSD 13.2 stable version using ZFS, the desired packages, I installed Windows 10 vm with bhyve, but I experienced frequent kernel panic crashes and after a few such events I run into "Mounting from ZFS: ... failed with error 5". I thought that I made something wrong with software installation so I reinstalled everything. After a few such cycles, I considered the possibility of a hardware problem and after the last mounting zfs issue I reboot the computer with an usb install media and in the shell, after importing the zpool i run
Code:
zpool scrub zpool0
Code:
zpool statusAfter
Code:
zpool0 clear ...So I sent the computer back to the hardware technicians who built it, but the problem is that in my hometown it seems that nobody have even a clue how to build a non-windows computer and about zfs, well, they don't even heard about it.
1. Is it possible that my computer configuration be the cause of the problems?
2. Now I cannot boot and login into my computer. Is it possible to check the /var/log/messages from the shell of the usb installer?
3. Is HD tune pro 5.70 a suitable tool for checking for I/O HDD errors if the disks are working under FreeBSD (this tool is used by the hardware firm to test the computer) ?
4. Can I install the package smartmontools from the shell of the usb install media in order to use smartcli command to check the disks ?
5. Any other guidance would be very much appreciated