Hi all,
We are experiencing a really strange issue that are driving us crazy to solve and we have not never experienced before.
We use a Supermicro enclosure with a LS3008 SAS+SATA controller and Freebsd 11.0. We know this version has reached EOL date and we are working to move-on. Nevertheless, the issue we are experiencing is quite strange and we are not pretty sure if it is directly related with this as it is not an expected behaviour, even with an relative old version.
We created 3 pools with 12 disks (6 TB) in RaidZ2 and we launched a couple of robocopy against one of the pools (/MT:10) We are using OPT1 interface which is a failover between 10GB Ethernet and 10GB FC, but data is being transferred by FC Interface. Each copy should transfer 18TB of data, filling the pool with 36TB. Initially, copy seemed to be working but, after a while, we began to obtain Read-Write errors in zpool status (even CKSUM) Once we began to obtain these errors, copy process continued but after some hours, disk began to be removed from pool and copies failed. Not only one or a couple of disks. Most of them were removed, causing pool degradation and finally data loss.
Reviewing system log, we obtained tons of CAM error messages for each disk (retries exhausted, write operation finished with errors...) Our first thought was that issue pointed to disks used in enclosures (WD60EFAX) as looks like they are not the best choice for ZFS. Strangely, launching a smartctl command against the disks do show that parameters as Reallocated_sector, Pending_sector, Uncorrectable (5,197,198...) looks like disks were not really damaged (all values were 0) But it is a fact that disks do not work properly because if we try to start the enclosure with a live-cd, we see the same CAM errors.
After replacing WD disks with Hitachi, a new 12 disks -RaidZ2 pool was configured and processes was relaunched. Unfortunately, we are experiencing more or less the same issue. Enclosure do not remove disks and pool still stands, but zpool status shows Read-Write errors after 30 hours. Copies are still being performed.
This behaviour has been observed, not only in one enclosure but in four. They are exactly the same hardware and firmware and are located in different data centre, so we have discarded a hardware failure (such a malfunctioning cable or electrical component) as we don't think there are 4 faulty components in different enclosures. Temperature issues have been also discarded as data centre temperature is ok and fans have been forced to work at 100%.
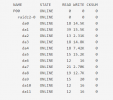
We are attaching some log files with errors in one of the disks (new disks), actual zpool status and dmesg to help understand the issue.
Our initial thought was perhaps the issue could be related with a heavy IO using FC link that may reach hard drives capacity (6GB) that might cause stress the disks until their limit. We could probably expect copy gets slow, enclosure do not respond to other requests, but not disks with fails or directly removed.
We are working with enclosure provider to try to fix the issue but we have open a post here just in case any other has experienced the issue and can provide some extra information which may help us understand this behaviour.
Thank you very much in advance.
We are experiencing a really strange issue that are driving us crazy to solve and we have not never experienced before.
We use a Supermicro enclosure with a LS3008 SAS+SATA controller and Freebsd 11.0. We know this version has reached EOL date and we are working to move-on. Nevertheless, the issue we are experiencing is quite strange and we are not pretty sure if it is directly related with this as it is not an expected behaviour, even with an relative old version.
We created 3 pools with 12 disks (6 TB) in RaidZ2 and we launched a couple of robocopy against one of the pools (/MT:10) We are using OPT1 interface which is a failover between 10GB Ethernet and 10GB FC, but data is being transferred by FC Interface. Each copy should transfer 18TB of data, filling the pool with 36TB. Initially, copy seemed to be working but, after a while, we began to obtain Read-Write errors in zpool status (even CKSUM) Once we began to obtain these errors, copy process continued but after some hours, disk began to be removed from pool and copies failed. Not only one or a couple of disks. Most of them were removed, causing pool degradation and finally data loss.
Reviewing system log, we obtained tons of CAM error messages for each disk (retries exhausted, write operation finished with errors...) Our first thought was that issue pointed to disks used in enclosures (WD60EFAX) as looks like they are not the best choice for ZFS. Strangely, launching a smartctl command against the disks do show that parameters as Reallocated_sector, Pending_sector, Uncorrectable (5,197,198...) looks like disks were not really damaged (all values were 0) But it is a fact that disks do not work properly because if we try to start the enclosure with a live-cd, we see the same CAM errors.
After replacing WD disks with Hitachi, a new 12 disks -RaidZ2 pool was configured and processes was relaunched. Unfortunately, we are experiencing more or less the same issue. Enclosure do not remove disks and pool still stands, but zpool status shows Read-Write errors after 30 hours. Copies are still being performed.
This behaviour has been observed, not only in one enclosure but in four. They are exactly the same hardware and firmware and are located in different data centre, so we have discarded a hardware failure (such a malfunctioning cable or electrical component) as we don't think there are 4 faulty components in different enclosures. Temperature issues have been also discarded as data centre temperature is ok and fans have been forced to work at 100%.
We are attaching some log files with errors in one of the disks (new disks), actual zpool status and dmesg to help understand the issue.
Our initial thought was perhaps the issue could be related with a heavy IO using FC link that may reach hard drives capacity (6GB) that might cause stress the disks until their limit. We could probably expect copy gets slow, enclosure do not respond to other requests, but not disks with fails or directly removed.
We are working with enclosure provider to try to fix the issue but we have open a post here just in case any other has experienced the issue and can provide some extra information which may help us understand this behaviour.
Thank you very much in advance.