Did you do another 'freebsd-update install' after the reboot?This might be a dumb question.
After doing the
freebsd-update fetch
freebsd-update install
on a 13.2-RELEASE-p4 FreeBSD 13.2-RELEASE-p4 GENERIC amd64 and after rebooting shouldn't it say FreeBSD 13.2-RELEASE-p5 GENERIC amd64?
Note, the freebsd-update install said there wasn't anything to install for P5.
Did you do another 'freebsd-update install' after the reboot?
Stickied. Can't make it any more prominent.
Mount the partition (if it's not mounted already)
mount -t msdosfs /dev/ada0p1 /boot/efi(Use the correct disk and partition for your system; look atgpart show)
cp /boot/loader.efi /boot/efi/EFI/BOOT/Bootx64.efiThe 'target' directory and filename (EFI/BOOT/BOOTx64.efi) is on a FAT filesystem, FAT isn't case sensitive, so the exact case may be different on your system, case doesn't matter. Certain installations may also have created a EFI/FreeBSD/loader.efi, copy /boot/loader.efi to that too, just for good measure.
Some older installations may have a created a buggy FAT partition. You could get an error saying loader.efi doesn't fit even though the filesystem appears to be large enough. Then you may need to newfs_msdos(8) it first.
user@server:~ $ gpart show nda0 nda1
=> 40 1000215136 nda0 GPT (477G)
40 532480 1 efi (260M)
532520 1024 2 freebsd-boot (512K)
533544 984 - free - (492K)
534528 4194304 3 freebsd-swap (2.0G)
4728832 995485696 4 freebsd-zfs (475G)
1000214528 648 - free - (324K)
=> 40 1000215136 nda1 GPT (477G)
40 532480 1 efi (260M)
532520 1024 2 freebsd-boot (512K)
533544 984 - free - (492K)
534528 4194304 3 freebsd-swap (2.0G)
4728832 995485696 4 freebsd-zfs (475G)
1000214528 648 - free - (324K)
user@server:~ $ zpool status
pool: poolname
state: ONLINE
scan: scrub repaired 0B in 00:00:28 with 0 errors on Sat Oct 28 04:46:03 2023
config:
NAME STATE READ WRITE CKSUM
poolname ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
nda0p4.eli ONLINE 0 0 0
nda1p4.eli ONLINE 0 0 0
errors: No known data errorsIt has to be done on both disks. If you only updated nda0 the system is going to fail to boot if that drive fails.but one thing I don't understand is why this only needed to be done to one disk?
It's not the same filesystem. The efi partition isn't mirrored. Only your ZFS pool is. Besides that, a BIOS/UEFI has no notion of mirrors, RAID or anything like that. It only loads stuff from a single disk. Don't have to keep this mounted in any case, only mount the efi partition if/when you update the boot code. Just leave it unmounted the rest of the time.but it wouldn't even let me mount nda1p1, even though it should have been the same filesystem.
It has to be done on both disks. If you only updated nda0 the system is going to fail to boot if that drive fails.
It's not the same filesystem. The efi partition isn't mirrored. Only your ZFS pool is.
# mount -t msdosfs /dev/nda0p1 /boot/efi worked just fine, but # mount -t msdosfs /dev/nda1p1 /boot/efi was giving an invalid fs type error (or something, I've already closed the kvm window so I can't verify). Verified several times that I ran the command correctly too, even paging up to the nda0 command I'd previously run and just arrowing over to replace the 0 with a 1. nda0p1 first, but I think it still would have mounted over top of it even so.root@server:~ # mount -t msdosfs /dev/nda1p1 /boot/efi
mount_msdosfs: /dev/nda1p1: Invalid argument
root@server:~ # mount -t msdosfs /dev/nda0p1 /boot/efi
mount_msdosfs: /dev/nda0p1: Operation not permittedThere was a bug in the installer that would never write the efi boot code on the second disk of a mirrored installation. Just newfs_msdos(8) it, and set up the same directory structure.but# mount -t msdosfs /dev/nda1p1 /boot/efiwas giving an invalid fs type error (or something
There was a bug in the installer that would never write the efi boot code on the second disk of a mirrored installation. Just newfs_msdos(8) it, and set up the same directory structure.
# dd if=/dev/nda0p1 of=/dev/nda1p1 or would I need to actually set it up by hand? I'll need to do this again on a server with 6 bootable disks later when I get home so that would be more expedient for me.a bug in the installer that would never write the efi boot code on the second disk of a mirrored installation.
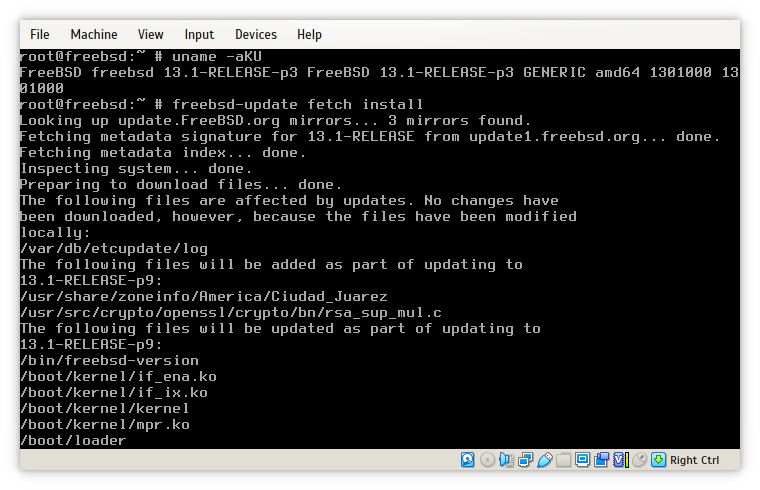
… Usefreebsd-update fetch install…
 mastodon.bsd.cafe
mastodon.bsd.cafe
I had the same habit (a single command), can't recall where it was learnt, I'll no longer promote it.
Probably better to run two separate commands, as shown in installation files.
Graham Perrin (@grahamperrin@bsd.cafe)
Attached: 2 images freebsd-update fetch install – did not install an update from (end of life) FreeBSD 13.1-RELEASE-p3 to 13.1-RELEASE-p9. It was necessary to run a different command before proceeding (with an upgrade): freebsd-update install #FreeBSD #update
freebsd-update fetch && freebsd-update install and freebsd-update fetch install and would't that be a violation of POLA?I always assumed putting multiple freebsd-update commands in a row are just executed in order …
… POLA?
install preceded by fetch in the same invocationI had the same assumption.
From the first screenshot, I no longer assume that there will be execution of all commands.
freebsd-update(8) COMMANDS:
– the user should not subsequently 'blindly' proceed as if there was success
- does allow for
installpreceded byfetchin the same invocation- does not guarantee that both will succeed
parse_cmdline () {
while [ $# -gt 0 ]; do
case "$1" in
# Commands
cron | fetch | upgrade | updatesready | install | rollback |\
IDS | showconfig)
COMMANDS="${COMMANDS} $1"
;;
esac
shift
doneget_params $@
for COMMAND in ${COMMANDS}; do
cmd_${COMMAND}
doneCode:get_params $@ for COMMAND in ${COMMANDS}; do cmd_${COMMAND} done
… the author of freebsd-update, cperciva@? …
Two of the comments were on 12th March 2019, I assume that all twenty-four were around the same time.
… an implicit return for no error. …
… I haven't the energy to chase it further …
")
Anyone, please: what's an implicit return in this case?
somefunc () {
if somecondition exit 1
if othercondition return 2
# implicitly return (0)
}ELI5
Latest commit to freebsd-update was done by Ed Maste.In Colin Percival's words:
Two of the comments were on 12th March 2019, I assume that all twenty-four were around the same time.
You're not having any AC in Nimbin ?Fair enough. The code's not that hard to follow, but I haven't the energy to chase it further (34°C 70% humidity)
freebsd-update here, it's just a matter of "don't ignore what the program is telling you"?OK, so the code executes the same as if invoked as 2 separate commands.
of course I was assuming that one checks the output - regardless if invoked one by one or combined.
So in essence, there's nothing wrong withfreebsd-updatehere, it's just a matter of "don't ignore what the program is telling you"?
… in essence, there's nothing wrong withfreebsd-updatehere, it's just a matter of "don't ignore what the program is telling you"?
